分布函数定量说明了广义集合的内部结构。
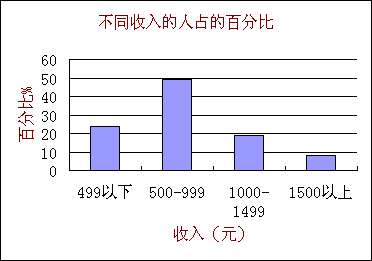
个人收入是个重要问题。我们也可以把它归为一个广义集合(个人是“个体”,收入是“标志值”)把个人收入问题提为“不同的收入的个人各有多少”问题。而它的答案是一个分布函数。国家统计局对我国12个城市的调查结果(引自1998年12月《百科知识》26页,估计是1997年的资料)是表3.2表3.2 不同的个人收入各有多少的一个调查结果(12个城市)
| 标志值x :每人每月收入(元) | 499以下 | 500-999 |
1000-1499 |
1500以上 |
| 个体数量n(相对):占的百分比 | 24% |
49% |
19% |
8% |
很显然这个统计恰好符合分布函数的格式。它描述了一种经济结构。
发现水的化学成分是氢二氧一在化学上是重要的事,如果把一个水分子看成是一个广义集合,并且把原子看成是个体,那么水的化学成分的发现也就是在原子水平上认识水分子这个广义集合的组成。这个广义集合的分布函数就是表3.3
表3.3 水分子的分布函数
| 标志x :原子序数
(或原子量) |
H氢的原子序数=1 (原子量=1) | O氧的原子序数=8 (原子量=16) |
| 个体(原子)的数量n: | 2 |
1 |
表3.4a 社会现象中的一些广义集合与分布函数
广义集合 |
个体名称 |
标志名称 |
分布函数要说明的问题 |
| 中国所有家庭 | 每个家庭 | 家庭的人口数 | 不同的人口数的家庭各有多少 |
| 地球上的国家 | 每个国家 | 国家领土面积 | 不同面积的国家各有多少 |
| 中国的农田 | 每亩农田 | 一年的产值 | 不同产值的农田各有多少 |
| 中国的机动车 | 每辆机动车 | 车的马力 | 不同马力的机动车各有多少 |
| 中国人 | 每个中国人 | 年龄 | 不同年龄的中国人各有多少 |
| 中国在奥运会上获奖 | 每个奖牌 | 奖牌等级 | 不同等级的奖牌各有多少 |
| 耀华股票 | 持有股票的人 | 持有股票数量 | 不同数量的股票的股民各有多少 |
| 进商场的所有顾客 | 每位顾客 | 顾客购物金额 | 不同购物金额的顾客各有多少 |
| 某市一天的电话 | 每次通话 | 通话时间长度 | 不同通话时间的电话各有多少 |
| 中国的国营工厂 | 每个国营工厂 | 职工人数 | 不同职工人数的工厂各有多少 |
不同年龄的中国人各有多少?这是个大问题,而表中恰好用一个广义集合的分布函数描述了这个问题。表中的其他个例也都有启发性。广义集合可以把很多社会问题提清楚,而分布函数可以对问题作出明确的回答。这说明社会科学的研究中应当应用广义集合。
在表中仅给出了广义集合对应的分布函数的物理含义。社会科学工作者应当在这种思路的指引下去寻找分布函数。每找到一个分布函数都意味着发现一个客观规律(定律、经验公式)。函数不是让社会学者讨厌的抽象概念,而是自己的朋友和助手。
表3.4b自然现象中的一些广义集合与分布函数
广义集合 |
个体名称 |
标志名称 |
分布函数要说明的问题 |
| 太阳系小行星 | 每个小行星 | 行星的质量 | 不同质量的行星各有多少 |
| 中国的煤矿 | 每个煤矿 | 煤矿的储煤数量 | 不同储量的煤矿各有多少 |
| 某年的地震 | 每次地震 | 地震释放的能量 | 不同能量的地震各有多少 |
| 一次暴雨过程 | 每平方公里暴雨 | 雨量 | 不同雨量的面积各有多少 |
| 全国的湖泊 | 每个湖泊 | 湖泊的面积 | 不同面积的湖泊各有多少 |
| 全国的土地 | 每平方公里土地 | 海拔高度 | 不同海拔的国土各有多少 |
| 一片西瓜地 | 每个西瓜 | 西瓜的重量 | 不同重量的西瓜各有多少 |
| 一片松树林 | 每棵松树 | 树龄 | 不同树龄的松树各有多少 |
| 人体 | 体内每段血管 | 血管的直径 | 不同直径的血管各有多少 |
| 一瓶氧气 | 每个氧分子 | 分子运动速度 | 不同速度的分子各有多少 |
我们不仅看到了很多广义集合,也看到了与它相伴的分布函数。现在的问题是每个具体的广义集合的分布函数是如何求得的。
求广义集合的分布函数的途径有两个。一个是从理论上求其分布函数,一个是对客观事实做观测和统计计算求出它的分布函数。从理论上求分布函数是理论工作(如后面介绍的最复杂原理等)的任务,这些以后再谈。现在介绍从观测调查的事实中得到分布函数的方法。
求分布函数首先要弄清楚什么是研究的客观事物(广义集合)、什么是它里面的(我们关注的)个体以及什么是要研究的标志这三个环节(把其他问题都排除在外)。下一步是明确什么是本问题中的“不同的标志值的个体各有多少”。求其分布函数就是回答上面的问题,这道理其实很浅显。
选举是现代政治活动的重要一环,大家对选举的过程也比较熟悉。这里就以它为例说明统计选票也就是求分布函数。首先明确什么是本问题中的广义集合、个体、标志和分布函数。表3.5可以把问题提清楚。表3.5 用新语言分析选举问题
广义集合 |
个体名称 |
标志名称 |
分布函数 |
所有的有效选票 |
每张选票 |
候选人 |
不同的候选人各有多少张票 |
是的,我们对统计选票过程很熟悉。最笨的统计方法是列出两个表。第一个表是原始资料表(即上一章介绍的广义集合的原始列表),它给出了每张选票的原始情况。
表3.6 把选票整理成一个原始列表
选票编号 |
1 |
2 |
3 |
4 |
5 |
6 |
.. |
.. |
.. |
100 |
被选举人 |
A |
B |
A |
D |
A |
C |
A |
A |
表里共有100张有效选票,而被选举人仅有A、B、C、D四位。利用这个表统计每个人的得票时我们中国人的做法是在黑板上用正字的多少表示每个候选人的票数(正字五笔,每笔代表一张选票,每有一张选票加一笔)。于是就有第二个表。例如它表3.7。 表3.7对原始列表的计票统计
被选举人 |
A |
B |
C |
D |
标志值 |
得票数 |
正正正正正正正正正正正正正正正 |
正正正 |
正正 |
正 |
个体数量 |
| 百分比% | 75% |
15% |
10% |
5% |
合计100% |
实际的选举统计工作可能比我们的做法还要简单,即仅列出第二个表就可以了。我们以一个最简单的例子用了最笨的方法得出了分布函数。其目的是说明从原始资料(也就是从所谓广义集合的原始列表)中求分布函数的过程。
概括地说从资料中求分布函数的步骤是:
1.明确什么是本问题中的广义集合、个体、标志和分布函数的格式; 2.把原始资料(每个个体的标志值)整理成上一章介绍的原始列表; 3.利用表中的原始资料再统计成表3.8形式。表3.8 把原始列表整理成分布函数的一般格式
标志值 |
x1 |
x2 |
x3 |
… |
xI |
… |
xk |
个体数量 |
n1 |
n2 |
n3 |
… |
nI |
… |
nk |
百分比 |
p1 |
p2 |
p3 |
… |
pI |
… |
pk |
从资料中得到一个分布函数相当于找到了一个经验公式。这本身就是有相当的科学价值。现在有很多工程师可以使用一些书本上现成的公式。但是自己从客观观测数据中发现一个经验公式的工程师并不多。有了广义集合的概念,知道每个广义集合必然伴有一个分布函数,这就为广大的工程师们发现新的公式(分布函数)提供了清楚的思路。