注:本文尚没有在刊物上发表过,未经本人许可不得转载。作者于2000,4,14
本文取自熵信息复杂性网站2002年5,25
-----
汉字的数学美--
汉字笔画与数量的数学公式
张学文
e-mail: zhangxw@mail.xj.cninfo.net
摘要:研究发现汉字的笔画x与该笔画汉字的个数y符合对数正态分布公式。
关键词:汉字,分布规律,对数正态分布
1.引言
汉字有数千年的历史,现在被世界1/5的人口使用着。其历时之长,用者之多在人类文化史上唯一的。数学是一种研究工具,在自然科学中得到了广泛应用,20世纪以来它也逐步应用到人文科学中。鉴于汉字的重要性用数学研究文字是历史趋势。
对于英文,大约在50年前人们就研究过各个英文字母在文献这出现的次数(频率)。此后又发现组成单词的字母个数与这个词的使用次数(频率)之间存在着反比例关系,它被称为Zipf法则[1]。对于汉字,我国也做了研究,出版过不同词汇的使用频率的资料。现在电脑里的汉字系统就利用这种资料,依出现频率从大到小排列汉字和词汇。显然,这对于提高汉字输入电脑的速度十分有益。
对于汉字,除了已经有统计分析资料外显然还需要研究其定量规律。本文就是这方面的工作。这里考虑的问题是:汉字的笔画有多有少,在所有汉字中,笔画的数量x与该笔画的汉字的数量y之间是否存在什么规律?本文发现它们有良好的函数关系,而且此函数可以用数学中的对数正态分布函数表示。
2.资料与统计
我们研究的对象是使用着的汉字全体。要研究的问题是不同笔画的汉字各有多少。要了解这个问题当然是翻字典。字典里肯定可以统计出不同的笔画的汉字各有多少。但是现代字典多数是以拼音为主线编的,统计起来很费力。为了便于统计,我们用了1987年印的1979年版的辞海[2]。
表1.是从词海中统计出来的不同笔画的汉字的个数。它显示出笔画过少或者过多的汉字都比较少,9-14画的汉字最多。
表1.不同笔画的汉字的个数
|
笔画 |
个数 |
笔画 |
个数 |
笔画 |
个数 |
|
1 |
3 |
13 |
1307 |
25 |
65 |
|
2 |
23 |
14 |
1188 |
26 |
34 |
|
3 |
74 |
15 |
1125 |
27 |
27 |
|
4 |
163 |
16 |
956 |
28 |
19 |
|
5 |
261 |
17 |
788 |
29 |
9 |
|
6 |
464 |
18 |
567 |
30 |
4 |
|
7 |
823 |
19 |
495 |
31 |
3 |
|
8 |
1084 |
20 |
370 |
32 |
0 |
|
9 |
1281 |
21 |
264 |
33 |
2 |
|
10 |
1357 |
22 |
208 |
34 |
0 |
|
11 |
1445 |
23 |
159 |
35 |
1 |
|
12 |
1571 |
24 |
121 |
36 |
1 |
3.数学拟合公式
资料已经揭示了笔画与汉字数量的基本关系,可否用一个参数不多的数学公式描述汉字笔画与该笔画汉字的数量的关系呢?研究发现,笔画x与汉字数量y的关系符合数学上的对数正态分布函数。其公式是
![]()
公式中16262是汉字(辞海)的总个数,μ是笔画数x的自然对数的平均值,其值为2.4739,σ是笔画的自然对数的标准差,其值为0.3827(平均值和标准差的计算公式与一般统计书的介绍相同,没有具体列出)。公式中来自资料的参数仅有这两个。这个公式可以计算出各个笔画的汉字的理论个数,它与实际资料的对比效果显示在图1.中。
图1.不同笔画汉字的实际数量(绿色)与理论数量(黄色)的对比图
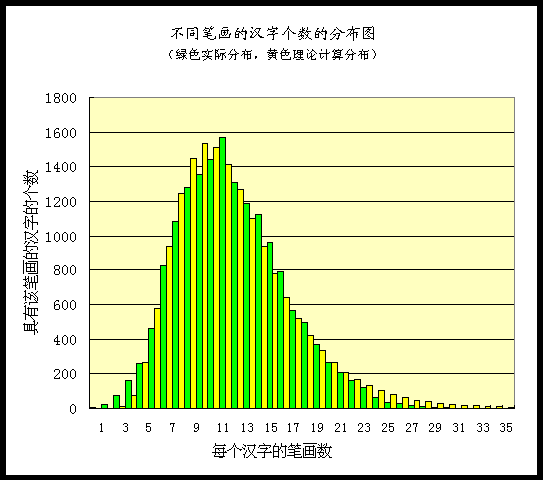
图1.中汉字的笔画数(从0-36画)列在横坐标上,而立柱的高度(纵坐标)代表了该种笔画的汉字的个数。绿柱是资料中的实际值(即表1.中 的值),黄柱高度是数学公式计算的值。
从图1. 看理论公式与实际资料的拟合是很好的。黄柱(理论)与绿柱(实际)的基本走势和具体的数值都比较接近。一个仅含两个参数的理论公式与这么多数据基本一致说明这个公式准确刻画了汉字笔画与数量的关系。
图1.说明我们可以用这个公式代表中国汉字笔画与汉字数量的关系。这对于汉字研究显然有理论价值。
4.简要说明
笔者是气象工作者,曾经发现过若干个气象领域的分布函数。后来我把这一类问题归结为一个模型:不同的某某某各有多少。把这个模型用于汉字,就可以归结为不同的笔画的汉字各有多少。
笔者还用最大熵(音商)原理解释了若干个分布函数(与本问题类似的公式,都是上述模型的个例)[3,4],在文献[3]中我们指出过利用最大熵原理和两个约束条件就可以得到对数正态分布函数。这两个条件是变量的对数的平均值为一个常数和变量的对数的标准差为另外一个常数。我分析汉字很可能满足这两个条件,而且没有其他非常重要的新条件要考虑。于是在得到了实际资料以后首先实验对数正态分布是否与实际一致,结果是一试成功。几千年慢慢形成的汉字竟然在总体上可以用一个数学公式描述看似偶然实际也体现了汉字的自身规律。
认识汉字的这种规律显然是我们对汉字研究的一个进步。人们对汉字体形之美已经欣赏多年,汉字蕴藏的数学之美也该当让大家知道。
参考文献与网页
高安秀树(沈步明,常子文译),分数维,北京,地质出版社,1989,68-69
辞海编辑委员会,辞海,上海,上海辞书出版社,1979(1987年印)
张学文、马力,熵气象学,北京,气象出版社,1992,201