字组的划分方法
――试论字本位理论的功用
邹晓辉
0756-5505041 qhkjy@yahoo.com.cn
519125 广东珠海井岸桥东恒美花园15-2栋201号
摘要
本文的中心思想是:用“音节总量控制模型”限定“字组的定义或划分”,即:给出“字组的划分方法”。本文是“字的形式化定义”一文的“姊妹篇”。首先,在形式体系中,采用“字”作为基本结构(形式)单位,对“字组”进行划分,即:“字组细分”。进而,从语言学家、普通用户、(领域)专家那里获取关于字组划分的信息或知识。因此,借助计算机和国际互连网,根据“音节总量控制模型”,所有用户可在任何时候或任何地方查询或重用“字组”。这也是汉语“字本位”理论功用的体现。
关键词:字本位、线串型结构、字组的划分方法
一、绪言
本文作为“字的形式化定义”的姊妹篇,进一步给出“字组的形式化定义”或“字组划分的标准化方法”,涉及:基础语言学与计算语言学交叉的研究领域。其特殊性在于:“字组定义形式化”或“字组划分标准化”,不仅涉及:符号识别、自然语言理解和知识表达,而且还涉及:代数多项式和字符多项式的应用。其重要性在于:在语汇的形式处理方面,体现了汉语“字本位”理论的功用。由于“字组定义存在歧义”或“字组划分缺乏标准”是当前汉语理论界“立、驳论”双方争议的焦点,所以,能否解决此问题是能否消除歧义、平息争端、达成共识、形成(汉语界齐心协力的)共为的关键。其研究途径是:探讨“线串型结构”论述“字组定义形式化”或“字组划分标准化”及其优越性。其局限性在于:仅从形式化与标准化的角度探讨字组的定义与划分。其基本假设是:把“字”视为“线串型结构”的“节点”(含:起点),于是,“字”不仅可被视为组配“(狭义的)字组”的“基本结构(形式)单位”,而且也可被视为一种特殊的(次广义的)字组,即:“一字组”。其贡献在于:为汉语“字本位”理论提供“字组的划分方法”,并且,在排除“字组定义”歧义的同时,确立“字组划分”标准,以及“字组”查询或重用的计算方法及公式。
二、综述
根据汉语“字本位”理论[1]可以归纳出以下关于“字组”的观点、原理和方法:
就字组的含义而言,把“字的组合”称为字组,并视为“从字到句的过渡性结构单位”。
就字组的分类而言,一方面,把字组区分(即:细分)为:二字组(作为重点考察对象)、三字组、四字组、...多字组;另一方面,又把字组区分(即:粗分)为:表达概念(辞)与表达结构(块)两种基本类型(属于:语汇一级的狭义字组,也是通常意义的字组,一般不需特别说明)。
就字组的构成而言,提出以核心字(即:在字组中位于中心地位的那个字)为向心与离心的组字法。
就字组的例证而言,指出《现代汉语词典》与《倒叙现代汉语词典》实际上就是以核心字为基础而编制的两本研究字组结构和字义关系的重要工具书。
《计算语言学文集》第4集“汉语语法研究所面临的挑战[2]”一文对汉语“字本位”理论的质疑,不仅涉及“字”(注1),还涉及其他一些重要的概念或术语,如,指出:在《语言论》[3]这一“字本位”专著中“字组”(353页)、“核心字”(365页)等,也都没有进行严格而又明确的定义(注2)。因此,影响了人们对汉语“字本位”理论的认识和理解。
可见,字组定义存在歧义是当前汉语界“立、驳论”双方争议的焦点。如不能消除这一歧义,就难以平息争端,而不平息争端,就难以达成共识,这样,要形成汉语界齐心协力共为的局面就有困难。
因此,能否根据语言事实说清楚“字组定义形式化”或“字组划分标准化”是很重要的。本文基于工程和应用两方面实践而提出以下建设性方法或方案。希望至少能有“抛砖引玉”的功效!
三、方法
1、方法概述
汉语“字本位”理论所述的“字组”包括“辞”与“块”,可视为:狭义的字组,在“文本总量控制模型(GTCM)”(注:本文仅讨论其汉语部分)中,位于“第5和6进阶层式[*1]”。广义的字组,由“GTCM的第5和6进阶层式”向两端延伸而来,如:逆向延伸其低端至“GTCM的第4进阶层式”便形成限定在语汇一级的次广义的字组,涉及:“字、辞、块”;“音节总量控制模型(GSCM)”就是以位于“GTCM的第4进阶层式”即“字”作为“基本结构(形式)单位”对“GTCM的第5和6进阶层式的狭义字组”实施“形式上的细分”而构成的。在此基础之上,就可深入一步对汉语语汇(即:次广义的字组)进行“内容上的字组细分”[通过“语言信息标注、常识信息标注、(学科或领域)知识信息标注”而实现。这将有利于:“海量人类基本知识的形式化表现”(如:CYC常识知识库、wordnet概念词典、encyclopedia百科全书)和“专家系统”(ES)的快速构建和及时改进或优化,同时,也将有利于:“计算机辅助(CA)汉语教学”和“机器翻译”以及“其它中文信息处理项目”在内容和形式的整合方面实施各种进一步的“字组划分”(具体作法在“工程融智学与应用融智学双向互动及优化实践(一种新颖的产生式教学)”的系列专论中介绍)]。
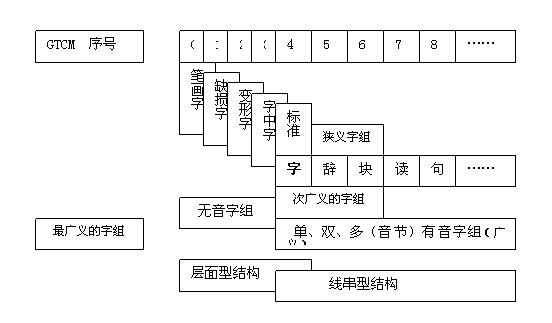
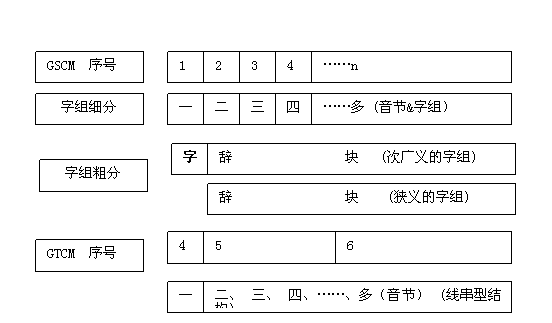
图1是字组粗分示意图。图2是字组细分示意图。
2、方法详述
(一)总体策略:
通过“字组定义形式化或字组划分标准化”,为下一步实现“义项解释字组化”奠定坚实的基础。
可选方法或途径:
a、着重研究语言事实外在现象方面的归纳方法(常规途径之一),
b、着重研究语言事实内在机理方面的演绎方法(常规途径之二),
c、强调内外统一的比较与穷举乃至对归纳和演绎的整合方法(常规途径之三),
d、强调借助计算机的运算处理速度和海量记忆存储能力以及通信网络的高效传输能力乃至便于输入输出反馈的人机协作界面,特别是对语言事实(含:外在现象与内在机理)进行科学的归纳、演绎、比较、穷举。本研究采用d方法或途径,并以形式化和标准化的工具或模型作为具体的实现手段。
(二)前期探索:
由于“协同智能计算语言数据库的设计方法[4]”一文(2002年11月)在“文本总量控制模型(GTCM)第5、6进阶层式”,仅仅涉及“辞、语”的字组粗分方式,所以,“义项语汇典例(SVDE)的总量控制模型――人机协作对采用汉语注释的语义词汇典例进行计量分析[5]”一文(2004年6月)进一步提出了“音节总量控制模型(GSCM)”的字组细分和拼字音节分划的标准化方法,即:把(次广义的)字组以单音节的“字”作为汉语的“基本结构(形式)单位”进行计量,字组数据库的各个表以及各个表的行和列均按自然数id自动编号实现对每一个格的自动测序定位,通过“三级标注[*2]”实现各种有针对性的序位变换或重组排序以满足用户(标准化、个性化、标准化与个性化两方面的各种结合的)需求。
“音节总量控制模型(GSCM)”多个系列(次广义的)字组细分一览表,在总量上等价于:“文本总量控制模型(GTCM)第4-6三个进阶层式”的(次广义的)字组粗分一览表。
中文信息处理领域一直以来都缺乏一套既便于前台直接表示自然语言文字又便于后台直接进行自然数计算的完整数学方法或工具。虽然与GSCM细分字组一览表id集合等价的“代数多项式”或“线性方程组”是实现总量控制的关键,但与GSCM细分字组一览表等价的“字符多项式[6]”却正好适合上述条件。
(三)方法步骤:
本文将进一步对汉语的“线串型结构”做深入细致的分析。
a、确定字组划分标准――参照系,即:
(1)字组粗分参照系:“文本总量控制模型(GTCM)”――“字组形式化定义”的依据;
(2)字组细分参照系:“音节总量控制模型(GSCM)”――“字组标准化划分”的依据。
b、根据标准划分字组――粗分与细分
(1)(广义)字组划分
图1是(广义)字组划分示意图。GTCM序号,表示:进阶层式。
首先,以“文本总量控制模型(GTCM)”为“参照系”,以“GTCM第4进阶层式”的“字”为“界”或“中介”,划分“层面型结构(如:GTCM第0-4进阶层式)”与“线串型结构(如:GTCM第4-8进阶层式)”。分别从逆向(即:由第4向第0进阶层式)与正向(即:由第4向第8进阶层式)两个方向,对汉语结构(形式)实施具体的划分。
“层面型结构”,涉及:“笔画字”和“缺损字、变形字、字中字”[均为:偏旁部首,属于:文字学和造字法的研究领域,可视为:不发音的(特殊的)无音(广义的)字组]以及“(标准)字”。
“线串型结构”,涉及:“(标准)字”(单音节)和“辞、块”[“双、多”音节,属于:要发音的(通常的)有音(狭义)字组]以及“读、句、…”。其中,“字、辞、块”只是粗分(次广义的)字组。
(2)细分(次广义的)字组
图2是(次广义的)字组细分示意图。GSCM序号:1,2,3,4,...,n,对应地表示:“一、二、三、四、...、多(次广义的)字组”一览表的系列序号。
以“音节总量控制模型(GSCM)”为“参照系”,以“GSCM序号为1的一览表中的‘字’为‘起点’”(准确地说是包含“起点”的“节点”或“划分尺度”)沿正侧或正向(即:由1向2,3,4,...,n的方向)逐一对“线串型结构”进行划分或细分,即:分别按照“GSCM序号(1,2,3,...,n)的系列一览表,存取“一、二、三、四、...、多(次广义的)字组”。
(3)形式化与标准化
为了进一步深入细致地探讨“(次广义的)字组”的“分与合”的机理、机制或法则,首先,“形式化”细分字组,然后,“标准化”细分字组,即:
构造“基于细分(次广义的)字组的电子表格或展示工具”(即:细分字组的各个系列一览表);
建立“基于(次广义的)字组细分的数学通式或计算模型”(即:∑aijxj=bi 系列一览表的id)。
其核心步骤的简化转述,即:
建立“系列一览表的id(自然数)与字符(自然语言)一一对应的“(次广义的)字组细分一览表”。
从“简化表述”或“直观实用”的角度考虑,可把该展示工具(电子表格)与该计算模型(数学公式)之间的对应关系,转述为:一系列“字符多项式”的形式,即:A={∑ n i x i }。
四、结果
1、(狭义)字组定义的形式化
汉语“字本位”理论所述的“字组”,即:“辞、块”,是:狭义字组,其形式化定义,特指:位于“文本总量控制模型(GTCM)第5、6进阶层式”这两个特定序位(即:GTCM序号5、6)的汉语结构(形式)。
2、(狭义)字组划分的标准化
在“文本总量控制模型(GTCM)”中,(狭义)字组粗分为:辞、块。
在“音节总量控制模型(GSCM)”中,(狭义)字组细分为:二字组、三字组、四字组、...、多字组。
3、(次广义的)字组的形式化与标准化
不仅GSCM序号:“1,2,3,4,...,n ”与“一、二、三、四、...、多(次广义的)字组的系列一览表”之间是一一对应的关系,而且,其中的各个系列一览表的id在∑aijxj=bi中的序位也都是唯一的。
(1)(次广义的)字组细分形式化,即:表格化。便于(次广义的)字组表示和标注的自动化。
(2)(次广义的)字组细分标准化,即:公式化。便于(次广义的)字组计算和统计的数学化。
4、(次广义的)字组的表示与计算
(1)用“id”(自然数)与“(次广义的)字组”(自然语言)“同义并列”且“一一对应”的方式,构造“细分(次广义的)字组”各个系列的一览表。
(2)其中,表格的“id”(自然数)部分与数学模型(即:∑aijxj=bi)的“特式”或“特例”(即:具体的算法和数据结构)等价。这是实现“(次广义的)字组”间接计算(批处理)的基础。
(3)其中,表格的“字组”(自然语言)部分与展示界面(如:以“重用、组合、轮排”等方式存取或调用)的标准化或个性化(即:有关具体的应用软件体现)等价。这是实现“(次广义的)字组”直接表达(自动化或计算机辅助)的基础。
(4)用“字符多项式”表达(2)计算模型(代数公式)与(3)展示工具(电子表格)的对应关系,便于寻找具体的分布函数或求解(∑aijxj=bi)的“特式”或“特例”。
5、用通俗的话转述(狭义)字组的形式化定义
从理论语言学与计算语言学结合的观点来看,“(狭义)字组”,作为汉语结构(形式),特指:由“字”按照一定的规则而组配的“线串型结构”,其特征在于:1、混音节(包括:双音节、三音节、四音节、…、多音节),2、线串形(如:由方块字组配的字符串,汉语拼音字符串可与之同义并列),3、义项的内容与形式之间呈“反变”关系,即:(狭义)字组,随着结构(形式)的增长,其义项(内容)反而减少。也就是说:具有义项发散性的字的多义项,将随着(狭义)字组的字数的增加而使组配的(狭义)字组的义项趋于收敛,即:外延大内涵小。“(狭义)字组”与“字”的本质区别在于:“(狭义)字组”可是多种结构形式,如:二字、三字、...、多字,而“字”只有一种结构形式(即:一字)且可作“线串型结构(形式)”的基本计量单位。
五、结论
综上所述,就“字、辞、块、读、句”而言,不仅汉语的基本结构(形式)单位只能是形式化定义的“字”,而且,汉语语汇一级的其它结构(形式),如:“辞、块”,或:“二字组、三字组、四字组、...多字组”,乃至扩展到汉语句法一级的其它结构(形式),如:“读、句”,或:“二字句、三字句、四字句、...多字句”,都可以“字”作为“基本结构(形式)单位”进行层层分解或组合。
结论:汉语的其它结构形式,如:“辞、块、读、句”等,没有一个比“字”更适合作“汉语的基本结构(形式)单位”。
(狭义)字组的形式化定义或划分,涉及计算语言学中文信息处理领域的所谓“汉语分词”难题(因为汉语没有与英语等拼音语言文字对应的“词”这个结构(形式),所以,对中文信息处理而言,“词的切分”是学界公认的难题!),如:对“辞、块”这一“粗分的(狭义)字组”很难实施形式化处理。
可是,一旦实现了“粗分(狭义)字组”与“细分(狭义)字组”的转换,情况就会大不一样。因为,“字组细分”之后,容易实施形式化和标准化处理,从而,为进一步实施个性化重用奠定了计算机辅助乃至自动化应用的坚实基础。这也就是基于汉语“字本位”理论的“(狭义)字组细分”的“形式化”与“标准化”的好处或优越性。具体应用举例如下:
1、在中文信息处理领域,可这样解决“(通常所说的)汉语分词”难题,即:
a、变“字组粗分”为“字组细分”,实现“形式化”和“标准化”;
b、变“(随时可能落入‘语义泥潭’中的所谓)汉语分词”为“(完全形式化和标准化的)汉语字组细分”,以便于计算机辅助和自动化标注:语言信息、常识信息、(学科或领域)知识信息。
c、进一步可构成:基于汉语(狭义)字组细分和“三级标注”的“静态字组”数据仓库。
d、在“静态字组”数据仓库的使用过程中,再进一步发展出相应的“动态字组”数据库,其中,重用部分,完全自动化;创新部分,完全实现“计算机辅助(CA)”。
2、在汉语教学领域,可这样优化教学过程及效果,即:
a、借助[基于“音节总量控制模型(GSCM)”的]“细分字组”数据(仓)库中集大成的“语言信息、常识信息、(学科或领域)知识信息”,改进或优化“计算机辅助(CA)教学”,如:改进或优化(作为母语的)“汉语教学”与(作为外语的)“汉外教学”的过程及结果。
一方面,可充分利用计算机批处理或自动化的高效率支持“计算机辅助(CA)教学”;另一方面,可充分借鉴或融合各类智能系统或领域专家们标注或精选的“语言信息、常识信息、(学科或领域)知识信息”,在教学实践中不断地改进或优化“二字组、三字组、四字组、...多字组”(乃至“二字句、三字句、四字句、...多字句”)等形式化或标准化的“汉语结构(形式)”――“动态字组”数据库与静态字组”数据仓库,不断地完善“计算机辅助(CA)标注(其中:个性化的标注与教学活动息息相关)”、“海量人类基本知识的形式化表现”(CYC)和“专家系统”(ES)。
通过上述两方面(如:“动态字组”数据库与静态字组”数据仓库,与“CA”“CYC”“ES”)的优化互动,既可帮助用户改进或优化“教学或训练”的过程及效果[如:熟练掌握汉语的“组字成语、组字成句、组语成句”的方法(其中包含汉语自身的一系列规律或法则,如:语法),达到“以简驾繁”的目的或效果],又可促使系统本身(如:“动态字组”数据库与静态字组”数据仓库及其后台软件程序和前台交互界面)不断地改进或优化。
b、通过“人人、人机、机机、机人”之间的高度协作和优势互补,把前述“以简驾繁”的过程及效果提升到足够“目标用户群”共享的程度,从而,显著地提高计算机辅助(CA)教学的智能化水平。
由于从(狭义)“字组”到“字”的分解过程的“进阶层式化”,特别是语汇一级“(次广义的)字组”结构形式的数量极限“可计算”,因此,确保:可在计算机辅助(CA)的条件下实现总量控制。如:在“字音”方面,只涉及:汉语拼音的400多个音节,加上声调的变化,总共也不过1000多个;在“字形”方面,只涉及:常用汉字和次常用汉字共3500个,通用汉字8000多个,Unicode列举的汉字2万多个;在“字义”方面,只涉及:已用自然语言描述并且公开公知的“语言信息、常识信息、学科或领域知识(概念)信息”的数量也是有限的(虽然,这对“一个人、一个单位、一个地方”来说,是一系列“天文数字”,但是,对 “一个跨国公司、一个国家、一个民族”而言,是能采用“产生式教学过程(另见:‘产生式教学法’一文,作者:邹晓辉,试验应用小组:华工计算机信息学院‘知识管理’研究生团队,华农外国语学院‘英语教学’本科生团队,吉林大学珠海学院‘英语教研室’教师团队,温州职业技术学院研究所‘应用课题’…)”来与浩大的“语言文字系统工程”和“学科知识系统工程”之间形成“优化互动”而“大大地简化”前述的“特式”或“特例”的具体“计算方式”的。尤其是在计算机和互连网普及的时代,如能充分利用本文的方法,那么,原先的“天文数字”也就可转化为“指日可待的实际工程项目的具体进度指标”。
上述蓝图如能一步一步地实现或推进,那么,改进或优化之后的整个汉语“字本位”理论体系的大厦,就不仅仅是建立在逻辑和数学等抽象科学的基础上,特别是:通过计算机科学技术的形式化处理,在汉语教学与中文信息处理的诸多实际应用中,还可发挥出它应有的功用。
六、讨论
有了字和字组的形式化定义,作为汉语“字本位”理论根基的“字”的含义和汉语“字本位”理论应用的“字组”的含义(涉及:字组的定义或划分)也就都不再有歧义。汉语理论界再也没有必要就“形式本位”问题而继续争论。从此,不仅汉语“字本位”理论的“根基”(在形式方面)牢固了,而且,汉语“字本位”理论的功用(在字组划分方面)也明确了。
对字和字组的形式化定义的探讨,不仅涉及“字组”的合成,还涉及“字组”的分解(如:字组的粗分和细分)。“字组”以“字”为基本结构(形式)单位,进行的划分是可计量的。
如果“辞、块”可视为“粗分(狭义)字组”的类型,那么,“二字组、三字组、四字组...多字组”则可视为“细分(狭义)字组”的基本类型。
如果“字、辞、块”可视为“粗分(次广义)字组”的类型,那么,“一字组(即:单个的字)、二字组、三字组、四字组...多字组”则可视为“细分(次广义)字组”的基本类型。
如果“字、辞、块、读、句”可视为“粗分(广义)字组”的类型,那么,其中,次广义的字组(如:字、辞、块),属于语汇的范畴;(加标点的)广义字组(如:读、句),则属于句法的范畴。
…………
随着汉语“字本位”理论的定性问题(字和字组定义形式化)和定量问题(字组划分标准化)的解决,汉语的“语言文字系统工程”和与之密切相关的“学科知识系统工程”也将提上议事日程。如:用于解释“字”的“义项”的“二字组(几十万)、三字组、四字组、...、多字组”细分一览表(这一形式化和标准化的语言结构形式体系,作者虽已初步实现但还有待在进一步的实验、中试和商品化的三级科技经济推广过程中逐步改进或优化!)如与“产生式教学过程”实现优化互动,那么,“语言信息、常识信息、(学科)知识信息的标注”也将随之而显著改观,即:由“少数专家与其弟子或助手参与的‘作坊’式知识加工”向“广大用户和各个领域专家与其弟子或助手参与的‘网络’式知识加工”转变。
借助计算机及其互连网,既利于人们发现“创新字组”,也利于人们重用“现有字组”。从而,借助计算机辅助(CA),显著地提高“(本文仅介绍汉语的)研究、教学、生产、应用、计算”的效率及效能。
例1,就汉语“字组”的两种组合方式[7]而论,还可进一步探讨或细化。
直接组合,以语序为主要手段,把两个或两个以上的语言单位直接组合成一个较大的语言(形式)单位。如:组字成语、组语成句、组字成句。涉及“联合、修饰、陈述、动宾、补充”等组合关系。
关联组合,以起关联作用的虚字(词)为主要手段,把两个或两个以上的语言(形式)单位连接起来组成一个较大的语言(形式)单位。如:组字成语、组字成句、组语成句。涉及“并列、承接、递进、选择、转折、因果、假设、条件”等组合关系。
例2,就汉语“字组”的强制搭配[8]而论,对固定搭配和特定搭配(包括:控制性搭配与呼应性搭配)的语义关系类别及其性质,还可进一步做计算机辅助(CA)研究或探讨。
例3,就英汉语汇对比[9]而论,广义语汇学(包括:语义学、辞源学、字典学、修辞学)与狭义语汇学(“字、辞、块”的性质、构成、意义及发展、语汇的构成及发展等规律),还可进一步做计算机辅助(CA)研究或探讨。
例4,就在计算机上实行汉语的双轨制[10]而论,也可进一步研究或探讨汉语字组及拼音形式与英语词语及音标形式之间,如何建立一一对应关系的问题。这是一个典型的人机协同研究或实验。
例5,就语言理论而论,对语音、语义、词汇、语法“四大要素”与语义、语法、语用“三个平面”乃至语音、语义、语法“三个方面”“两层结构”(即:表层结构与深层结构)等各种语言理论,也可进一步做有计算机辅助(CA)的比较研究。
以上例1-5的“(次广义的)字组”包括了“字、辞、块”或“词、词组、短语”等粗分形式。
七、图
图1是“(广义)字组划分”示意图。
图2是“(次广义的)字组细分”示意图。
尾注
注1:邹晓辉“字的形式化定义--试论字本位理论的根基”[汉语“字本位”理论专题研讨会论文(短论之一)]2004年11月17日光明网[EB]
http://www.gmw.cn/03pindao/lunwen/show.asp?id=2339
注2:邹晓辉“字组的划分方法--试论字本位理论的功用”[汉语“字本位”理论专题研讨会论文(短论之二)]2004年11月27日光明网[EB]
http://www.gmw.cn/03pindao/lunwen/show.asp?id=2471
注3:邹晓辉“字与字组的关系--试论字本位理论的发展”[汉语“字本位”理论专题研讨会论文(短论之三)]2004年11月27日光明网[EB]
http://www.gmw.cn/03pindao/lunwen/show.asp?id=2472
参考文献
1、徐通锵《基础语言学教程》2001年2月北京大学出版社,19-36页,178-237页[M]
2、北京大学计算语言学研究所《计算语言学文集》第4集“汉语语法研究所面临的挑战(98现代汉语语法学国际学术会议第一次全体大会宣读)作者:陆俭明、郭锐”2000年12月,1-19页[C]
3、徐通锵《语言论--语义型语言的结构原理和研究方法》1997年10月东北师范大学出版社,295-442页[M]
4、邹晓辉“协同智能计算语言数据库的设计方法(2002年11月)--支持语言文字系统工程与全球语言定位系统的一个实施例”(此条也可视为:尾注) 光明网论文发表交流中心[EB]
http://www.gmw.cn/03pindao/lunwen/show.asp?id=2274
5、邹晓辉《第五届(国际)汉语词汇语义学研讨会论文集》“义项语汇典例(SVDE)的总量控制模型--人机协作对采用汉语注释的语义词汇典例进行计量分析 ”新加坡 2004年6月,281-286页[C]
光明网论文发表交流中心[EB]
http://www.gmw.cn/03pindao/lunwen/show.asp?id=2271
6、张学文《组成论》中国科学技术大学出版社2003年12,44-56页,246-252页[M]
http://potentialscience.org/ [EB]
7、张志公《汉语辞章学论集》“汉语简论”(1996年人民教育出版社),每一页[C]
8、南开大学《语言学论辑》“词语强制搭配的语义关系类别及其性质(作者:刘叔新)”(北京语言学院出版社1996年8月),1-17页[C]
9、喻云根《英汉对比语言学》北京工业大学出版社1994年12月,69-99页[M]
10、苏培成等《语文现代化论文集》“发挥汉语拼音在信息时代的作用(作者:冯志伟)”商务印书馆2002年10月,41-44页[C]
致谢
北京大学中文系基础语言学教研室徐通锵教授与洛阳外国语学院计算语言学教研室易绵竹教授在百忙中阅读了本文的初稿,前者从基础语言学专家读者的角度给予了作者珍贵的提示,后者从计算语言学专家读者的角度给予了作者宝贵的鼓励,在此作者向他们表示真诚的谢意!
同时,还要感谢作者的母亲和妻子给予的关怀和帮助!
没有上述各位的关心和帮助,此文难以在如此短的时间内修订完稿,并与汉语“字本位”理论专题研讨会的各位专家见面(指:论文公开)。希望它能起到“抛砖引玉”的作用!
最后,还要感谢汉语“字本位”理论专题研讨会组委会提供这次机会!特别要感谢汉语“字本位”理论创立者徐通锵教授给本文提供汇编进入论文集的机会!
THE PARTITION METHOD ON CHINESE WORDS GROUP
――ON USING THEORY OF WORD(CHARACTER) AS ESSENTIAL UNIT
ZOU XIAO HUI
BEAUTIFUL-GARDEN BUILDING 15-2 NUMBER 201 IN ZHU-HAI 519125
Abstract
It is the main idea of this paper that THE PARTITION METHOD ON CHINESE WORDS GROUP has been limited by GSCM(Gross Syllable Control Model).This paper is the companion volume with "THE DEFINITION IN SYSTEM OF FORM ON CHINESE WORD". First of all, Chinese words group can be measured off by using Chinese word as basic unit in system of form. And then, any information on partition of Chinese words group can be gotten from linguists, ordinary users and experts. So,according to GSCM with computers and internet mathematically, all users can inquire or reuse “Chinese words group” in anywhere or in anytime. That is ON USING THEORY OF WORD(CHARACTER) AS ESSENTIAL UNIT too.
Keywords
WORD (CHARACTER) AS ESSENTIAL UNIT, LINEAR STRUCTURE, THE PARTITION METHOD ON CHINESE WORDS GROUP