字的形式化定义
――试论字本位理论的根基
摘要
本文中心思想是:用“文本体系”或“音节体系”在形式上限定“字的定义”,即:给出“字的形式化定义”。“文本体系”意指“文本总量控制模型”。“音节体系”意指“音节总量控制模型。作为一种计算机辅助的方式,“文本体系”或“音节体系”,既能以数学形式用于计算机和国际互连网帮助用户学习汉语和机器翻译,同时,也能确立“形式化定义的字”即“作为基本结构(形式)单位的字”在“整个汉语(形式)体系”中“根基”地位。
关键词:字本位、线串型结构(字组)、字的形式化定义
一、绪言
字的定义,属于:基础语言学研究领域。本文的特殊性在于:定义方式的“形式化”,而这涉及认知心理学的符号识别方法、计算语言学的自然语言理解方法和人工智能的知识表达方法。其重要性在于:汉语“字本位”理论的根基是否牢固,与字的定义是否能够“消歧(即:消除歧义)”紧密相关,所以,这是当前汉语理论界“立、驳论”双方争议的焦点。本文作者认为:“字的定义”只有“形式化”才能“消歧”,否则,就难以平息“争端”,没有“共识”,哪来(汉语界齐心协力的)“共为”?本文报道的研究途径是:通过探讨“层面型结构”与“线串型结构”以及“作为两者迭交形式的‘字’的定义”的形式化方法,说明“如何消除‘字的定义’的歧义”以及“什么是字的‘形式化’定义”和这种方法的“优越性”。本文的限制领域或局限性是:从“形式化”的角度探讨“汉语的基本结构单位”。其基本假设是:如果汉语的结构单位都是“线串型结构”,而其中的基本结构形式必然位于这种“线串型结构”的起点,那么,“字”就是汉语的基本结构单位,因为,只有“字”正好位于这种“线串型结构”的起点。本研究的贡献在于:不仅从结构形式的角度,为汉语“字本位”理论提供了“字的形式化定义”的方法,可以有效地实现“字的定义”的“消歧”,同时,本文还从概念内容的角度,特别是从内容与形式统一的角度提出了一系列值得进一步探讨的问题。
二、综述
《基础语言学教程》[1](简称:教程)指出:语言基本结构单位是驾驭语言系统的枢纽。以语言基本结构单位为“纲”,比较汉语和英语等印欧系语言在结构上的异同,揭示不同语言的特点,进而讨论语言结构的基本原理。如:《教程》作者仔细比较研究了汉语、英语、俄语等一些语言的结构单位的异同之后总结出来的假设(即:确定语言基本结构单位的原理),即:语言基本结构单位的三个特点(即:三条标准):现成性、离散性和语言社团中的心理现实性。
然而,本文作者却发现:此原理,可以进一步研讨。首先,语言,有:形式与内容两个方面,因此,其基本结构单位,也有:形式与内容两个方面,如:符号与概念。其次,特点(标准),也有一个针对性的问题,如:它们是针对:形式或内容,还是两方面都针对?接下来,就自然是:一系列的分析、比较或研究。本文将重点进行“形式”方面的研究。
《教程》作者还认为:据此原理可断定:英语等印欧系语言的基本结构单位有两个,即:词和句子,而汉语只有一个,这就是:字。不仅因为,(汉语的)字[或(英语的)词和句子],是:语言研究应该首先抓住的基本结构单位,而且还因为,以此为基础逐层推进,可进一步弄清楚其它结构单位的性质、特点和它们的各种构造规则。显然。字是汉语“字本位”理论的根基。因为,汉语“字本位”理论,确立了“字”在该理论中的重要地位,具有“根基”的性质。
这个“根基”是否牢固呢?学界同行中有人提出了尖锐的质疑。例如:《计算语言学文集》第4集(2000)“汉语语法研究所面临的挑战[2]”一文就正是针对“字的定义”这个汉语“字本位”理论的“根基”提出了十分明确的质疑:
汉语“字本位”理论跟以往的语法理论完全不同。《教程》作者在《语言论》[3]这部专著中一再强调“字”是“汉语句法的基本结构单位”(11页),“汉语的结构以字为本位,应该以字为基础进行句法结构的研究”(13页)。质疑者指出:这是“字本位”的核心观点。可是,对“字”这个最核心的概念、使用最频繁的术语却并未给出严格明确的定义,而只是从不同角度做了一些说明。如:“字是形、音、义三位一体的结构单位”(266页);“字是汉语结构的枢纽,是语音、语义、词汇、语法的交汇点”(徐通锵1988a);“‘字’是汉语对现实进行编码的基本单位”(433页);“‘字’是汉语结构的枢纽、结构关联的基点”(433页);“字是汉语的基本结构单位,也是最小的结构单位”(434页);“我们把字看成汉语句法的基本结构单位”(11页);“我们把‘字’定义为:语言中有理据的最小结构单位”(17页);等等。这些说明,其含义并不一致(本文作者注:质疑者指出了作为汉语“字本位”理论的“根基”的“字的定义”存在“歧义”),让人难以理解“汉语句法的基本结构单位”的字到底是指什么。“有理据”的含义很不确定。目前哲学界和语言学界对“理据”的理解和看法,因人而异。由此可见,关于字的定义“很缺乏操作性”。这不能不影响人们对字本位理论的认识和理解。
在《语言论》(1997)之后几年出版的《教程》(2001)也说:字义的特点是概括性、民族性、模糊性。似乎并没有针对质疑(本文作者注:“汉语语法研究所面临的挑战”一文在1998现代汉语语法学国际学术会议第一次全体大会宣读)做出进一步的应对或论述。
既然如此,怎样才能给“字”这个概念或术语下一个严格而又明确的定义呢?“字的定义”的“操作性”的问题如何才能解决好呢?“字的定义”这个汉语“字本位”理论的“根基”存在的“问题、不足、缺陷或漏洞”能够弥补好吗?
显然,“字的定义”能否“消歧”?这将直接涉及汉语“字本位”理论的“根基”是否牢固的问题。
从汉语界“立、驳论”双方争议的焦点来看,“质疑”是针对汉语“字本位”理论的“根基”而来的。
以下试图科学地回答上述“根基”问题――提供“字的形式化定义方法”,旨在抛砖引玉。
三、方法
首先,确立:大前提。
从方法论的角度,确立本文作者的基本观点,即:对“字的定义”这个汉语“字本位”理论的“根基”问题的解决,不能仅仅建立在“因人而异”的所谓“理解”或“看法”的基础之上。换言之,只有遵循“形式化”的途径,才能把汉语“字本位”理论的“根基”建立在逻辑和数学的坚固基础之上。否则,难免会陷入“公说公有理,婆说婆有理”的非形式化的议论“怪圈”之中,即:“靠‘人气’或‘势力’决定‘理论’的优劣”(这显然不是严谨的科学态度和方法!)。
在此,“非形式化的议论”,指:基于内容的议论,它区别于:基于形式的推理和计算,即:“形式化的推理和计算”。众所周知,“非形式化的议论”,往往难以达成“共识”,“形式化的推理和计算”,则容易形成“共为”而不限于达成“共识”。
接着,明确:小前提。
从方法的角度,明确本文作者的基本方法――字的形式化定义方法,即:
(一)前期探索或研究方法(主要是基于文字和表格的准形式化方法):
a、在“语言及语义信息的统一参照系[4]”一文(2000年12月)中,本文作者曾指出:汉语的字和英语的词的最大不同是:在“基本笔画、偏旁部首、字、字组”的形式系列中,字以前是“非线性结构”,字以后是“线性结构”而且是多音节,字是单音节而且位于前后两种结构的交汇处;在“字母、词素、词、词组”的形式系列中,词的前后都是“线性结构”,而且词本身既可以是单音节也可以是双音节甚至还可以是多音节。由此而产生其它一系列语言结构形式的不同,其中蕴涵着具体的语言文字的构造机理和重用法则。
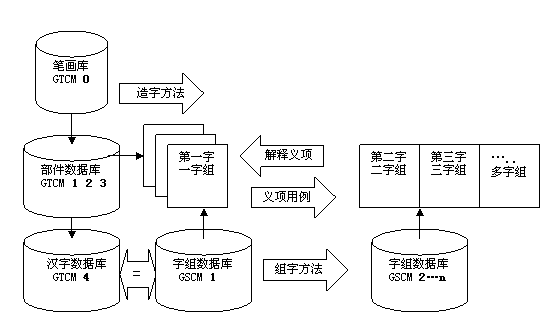
b、在“协同智能计算语言数据库的设计方法[5]”一文(2002年11月)中,本文作者还曾以“基本笔画、(不成字、变形字、字中字)三种偏旁部首、字、辞、块(语)、读、句、....”的方式,建立了“文本总量控制模型(GTCM)”系列一览表(对应于:相应的线性代数方程组),其实施例涉及:0、1、2、3、4、5、6、7、8、9、10、11、12个基础表,以及它们组成的语言文字数据库。其中,0-12简称:(自然语言或语言文字的13个)进阶层式,体现了语言进化发展不同阶段各个层次的具体结构形式的变化特点和规律。
c、在“义项语汇典例(SVDE)的总量控制模型--人机协作对采用汉语注释的语义词汇典例进行计量分析[6] ”一文(2004年6月)中,本文作者也曾经指出:1、就古代汉语和现代汉语中与传统一脉相承的语言现象而言,认同“字本位”。2、就现代汉语中吸收西方语言而发生显著改变的语言现象而言,主张“字组细分”。汉语的混音节“线串型字组”(如:汉语的“辞”“块”,与之对应的是英语的“词”“语”)是单音节“层面型字组”(汉语的“字”)与英语的混音节“词语”之间无歧义连接(同意并列)的纽带 (旨在保证“双语”的“义项”形式化“转换”或“对译”)。同时,根据“字组细分”的观点和“拼字音节”的分划方法,把所有的汉语“字组”以单音节的“字”作为“汉语的基本语言(形式)单位”进行计量和排序(1~n),建立了“音节总量控制模型(GSCM)” 系列一览表(对应于:相应的线性代数方程组),其实施例是:在“字组”(词汇一级),分为:1~n个系列的“字组细分”一览表[等价于“文本总量控制模型(GTCM)”的第4~6进阶的“字组粗分”一览表]。
(二)当前探讨或研究方法(由准形式化发展到纯形式化方法,包括:抽象与直观的方法):
a、具体策略
一般而言,任何一个字的含义都可能有多个义项,但是,作为一门科学学科的汉语“字本位”理论的“字的定义”,应无歧义。因此,要么从“字”的现有“义项”之中选出一个并确定其含义的“唯一性”(这是基于主体之间的约定方法),要么根据一定的参照系给出一个具有唯一性的科学定义(这是基于客体的标准化方法)。本文采用后一种方法。
b、具体途径
汉语“字本位”理论的“字的定义”既然选定了“基于客体的标准化方法”,那么,确立“参照系”或“标准”的“形式体系”就是唯一可行的途径。只有以此途径确立的“字的形式化定义”才是汉语“字本位”理论的“字”的科学含义。“形式化”是基于“形式体系”而言的。
只有采用“形式化”定义的方法,才能消除所有可能的“歧义”。不给“(有意或无意、主动或被动的)误解”留下任何借口或路径。
c、具体方法
首先,确定:具体的“参照系”,即:“文本总量控制模型(GTCM)”。
表1是说明“GTCM”的“0-8”个粗放“进阶层式”一共九个系列一览表的总表。
图1是说明代表“GTCM”的“0-8”个粗放“进阶层式”一览表的具体“数码”与对应的“文字”描述或称谓之间一一对应关系的简化示意图。
然后,根据上述参照系的具体形式体系,确定“字”的“形式化”定义。
(1)从两个方向解析“字与字组的关系”的方法,即:从“层面型结构”与“线串型结构”两个方面,或:从表1或图1中“4”的上下或左右两个方向的解析入手(即:具体的“形式化定义的方法”)。
两个方向:
一个方向是逆向,指:在表1或图1 的“进阶层式”中,“4”与“0、1、2、3、4”关系;
一个方向是正向,指:在表1或图1 的“进阶层式”中,“4”与“4、5、6、7、8”关系。
什么是“层面型结构”?
“层面型结构”,指:位于“0、1、2、3、4”诸“进阶层式”的成员,因其结构形式在计算机分析过程中呈现出“层面特征”而得名。
什么是“线串型结构”?
“线串型结构”,指:位于“4、5、6、7、8”诸“进阶层式”的成员,因其结构形式在计算机分析过程中表现出“线串特征”而得名。
(2)从“层面型结构”与“线串型结构”的“迭交”之处,解析“字与字组的关系”的方法。
“层面型结构”与“线串型结构”如何“迭交(即:交叉重叠)”?
“迭交”,指:在表1或图1 的“进阶层式”中,位于“0、1、2、3、4”与“4、5、6、7、8”的“迭交”之处的“4”这个唯一的“进阶层式”成员(即:“字”的结构形式)。
通俗的讲就是:
当位于“0、1、2、3、4”终点的时候,“字”作为“层面型结构”(涉及:字内的文字符号之间的组合)的构造形式,表现为:“文字”这一结构形式;当位于“4、5、6、7、8” 起点的时候,“字”作为“线串型结构”(涉及:字外的字组符号之间的组合)的构造形式,表现为:“语言”的结构形式,而且是:“基本结构(形式)”。
(3)从“层面型结构”与“线串型结构”迭交的“条件”来看,“字”这个特殊的结构形式可以作为汉语的其它“结构形式”的计量“单位”,解析“字与字组的关系”的方法。
“层面型结构”与“线串型结构”迭交的“条件”是什么?
迭交的“条件”是:在位于“0、1、2、3、4”的“层面型结构”与“4、5、6、7、8”的“线串型结构”之间,同时存在“4”即“字”这个位于“迭交之处”的“进阶层式”。
进一步,因为“4”即“字”这一“进阶层式”的“结构形式”在形式上正好是构成“5、6”即“辞、块”的“基本形式”,具有“可重复、可测量、可计算”的形式特征,所以,就可在语汇一级把较为粗放的“参照系”[即:“文本总量控制模型(GTCM)”]发展成为精细的“参照系”,即:“音节总量控制模型(GSCM)”,从而在“4、5、6”即“字、辞、块”的范围,实现:基于“字”这一“基本结构(形式)单位”的“字组细分”。
四、结果
字的形式化定义:
定义1
汉语“字本位”理论所述的“字”,特指:位于“文本总量控制模型(GTCM)”第“4” 这个特定序位的“进阶层式”的所有单个的“汉语结构形式”。
表1是说明“GTCM”的“0-8”个粗放“进阶层式”一共九个系列一览表的总表。
图1是说明代表GTCM的“0-8”个粗放“进阶层式”一览表的具体“数码”与对应的“文字”描述或称谓之间一一对应关系的简化示意图。
定义2
汉语“字本位”理论所述的“字”,特指:位于“音节总量控制模型(GSCM)”第“1” 这个特定序位的“进阶层式”的所有单个的“汉语结构形式”。
公式1是抽象表示“GSCM”的数学形式,说明“1-n”个精细“进阶层式”的“n”(多)个系列一览表及其总表,都可以表示为:线性代数方程(组)。
图2是说明代表GSCM“1-n”个精细“进阶层式”一览表的具体“数码”与对应的“文字”描述或称谓之间一一对应关系的简化示意图。
上述定义1和定义2是等价的。由此定义的“字”的集合,不仅包括了Unicode中的所有“汉字”,而且,还包括了所有将归入Unicode中的“字”或“汉字”,也包括“FONTS”中用于“显示”、“打印”或“输出”的各种形式的“字”或“汉字”。它们是构成“字组”或“线串型结构”的基本结构(形式)单位。
据此生成的“字的定义”的优越性表现在哪里?
据此生成的“字的定义”的优越性表现在它的“无歧义性”。
例如:位于“文本总量控制模型(GTCM)”第4“进阶层式”的“字”,一方面,可视为:第“0、1、2、3、4”进阶层式的高端或终点,另一方面,又可视为:第“4、5、6、7、8、...”进阶层式的低端或起点。因为,位于第“0、1、2、3、4”进阶层式的“基本笔画、(不成字、变形字、字中字)三种偏旁部首、字”,充其量都只是限于“方格”或“方块”之中的“层面型结构”的某个页面或层面;而位于第“4、5、6、7、8、...”等一系列粗放“进阶层式”的“字、辞、语、读、句、....”或位于“音节总量控制模型(GSCM)”第“1,2,3,…” 等一系列精细“进阶层式”的“一字组、二字组、三字组、…”则都是由上述“方格”或“方块”组成的“线串型结构”的某一占据“1、2、3、......”个方格“线性字串”。其中,只有“字”同时位于“文本总量控制模型(GTCM)”(第4“进阶层式”这个特定序位)与“音节总量控制模型(GSCM)”(第1个单音节一览表)“交集或并集”的一览表之中。显而易见,“字”既属于“层面型结构”的高端或终点,又属于“线串型结构”的低端或起点,而且,两个端点是“迭交”在一起的。
定义3
从基础语言学与计算语言学结合的观点来看,也可以说:“字”,作为汉语的基本结构(形式)单位,特指:位于“层面型结构”与“线串型结构”的“迭交之处”的那类汉语结构形式,其特征在于:1、单音节,2、方块形,3、多义项(其中,各个“义项”的“等价”形式,就是一系列与各个“义项”一一对应的“字组”,详细内容将在与本文及其“姊妹篇”的“字组的划分方法”一同构成“三部曲”的“字与字组的关系”一文中涉及“义项解释”的“形式化”或“字组化”的“义项本位”部分专门论述)。
图3说明“GTCM”与“GSCM”的两个“参照系”同时给出的“字的形式化定义”,即:表面上展示“字与字组的关系”,背后实际上都有相应的数据库在支持。
上述定义1、定义2和定义3是等价的。
五、结论
综上所述,本文给出“字的形式化定义”的前提和结论如下:
1、大前提
任何一种语言结构(形式)单位,均可以“文本总量控制模型(GTCM)”与“音节总量控制模型(GSCM)”的方式“形式化”。
2、小前提
以“文本总量控制模型(GTCM)”与“音节总量控制模型(GSCM)”的方式“形式化”的各个语言结构单位,在“GTCM”与“GSCM”这两个“参照系”中,均有其特定的“序位”。
3、结论
“字”作为一种特定的语言结构(形式)单位,在“文本总量控制模型(GTCM)”与“音节总量控制模型(GSCM)”中,也有其特定的“序位”。
由此可见,本文给出“字的形式化定义”是唯一的、无歧义的。
六、讨论
本文作者认为:虽然从形式结构方面看,汉语的基本结构(形式)单位只能是字,这将成为一个显而易见的事实。但是,如果从概念内容方面看,问题并没有这么简单。如果从内容与形式统一的角度看,那么,至少还有以下一系列问题或相应的情况值得进一步关注、探讨或交流。
1、如果仅仅就古代汉语和现代汉语中与之(古代汉语)一脉相承的语言现象而言(例如:成语),那么,“字本位”显然是成立的。
2、如果仅仅就现代汉语中吸收了西方语言的东西而发生显著改变的语言现象而言,那么,“本位”问题会比较复杂。其理由如下:
a、首先,“字本位”、“词本位”、“短语本位”、“小句本位”等,虽然旨在讨论汉语的基本结构(形式)单位,但是,却都夹杂了“非形式化”的内容。
b、其次,如果仅仅从形式方面来区分汉语的基本结构(形式)单位,那么,问题会非常清楚。例如:本研究对“字”和“字组”的定义(其中“字组”部分见本文的姊妹篇“字组的划分方法”),就是这样的,即:采用“形式化”的方法。
c、再次,必须指出:上述各“本位说”的区别主要在于各自形式的不同,一旦涉及内容问题立即变得复杂起来。例如:当“字”、“词”、“短语”、“小句”等表示“相同的概念”或指称“同一个物象”的时候,立即产生“形式歧义”。
d、最后,必须指出:就表达“概念”或“对象”而言,“字”、“词”、“语”的区别,主要在于“内容”方面而非“形式”方面(其中“内容”方面见与本文及其姊妹篇一道构成三部曲的另一篇文章“字与字组的关系”)。
3、从整体上看,无论是“字本位”还是“词本位”或是“短语本位”乃至“小句本位”,都恰似“盲人摸象”一样,都仅仅摸到了(汉语这个)“大象”的一个(非形式化的内容)部分。
4、尽管如此,这仍是非常了不起的!因为(汉语这个)“大象”的确太大,致使任何个人的经历或阅历要想统观全局且一览无余都难以想象。
总而言之,如果单从结构形式方面看,那么,“字本位”显然有其特殊的优势。
众所周知,凡有多个结构(形式)单位存在,就必定存在一个基本结构(形式)单位。由于从外语借用或导入的“词”,对汉语来说,可是“一字组(即:单个的字)、二字组、三字组、...多字组”中的任何一个(“短语、小句”也如此),只有“字”位于最基本的位置。所以,仅就形式而论,汉语的基本结构(形式)单位,非“字”莫属。
这样看来,“字的形式化定义”的确可解决“字本位”理论的“根基”的定性问题。
接下来,就该探讨“字组的划分方法”涉及“字组”计算的定量问题了。再进一步,才便于较为深入地研究“字与字组的关系”这一既涉及结构又涉及程序的复杂问题。
七、图、表、公式
图1
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
笔画 |
不成字部首 |
变形字部首 |
字中字部首 |
字 |
辞 |
块 |
读 |
句 |
图2
|
1 |
2 |
3 |
…….. |
n |
|
一字组 |
二字组 |
三字组 |
……... |
多字组 |
图3
表1
|
编号 |
进阶 |
汉语 |
拼音 |
英语 |
|
1 |
0 |
基本笔画 |
字母表 |
26个字母 |
|
2 |
1 |
不成字偏旁部首 |
|
词头和词尾 |
|
3 |
2 |
变形字偏旁部首 |
|
前缀和后缀 |
|
4 |
3 |
字中字偏旁部首 |
|
词根 |
|
5 |
4 |
单音节的“字”(基本结构形式单位) |
单音节 |
混音节单词 |
|
6 |
5 |
复音节的“辞”(字组)离心与向心 |
多音节 |
多音节词组 |
|
7 |
6 |
多音节的“块”(字组)含两种成份 |
多音节 |
多音节短语 |
|
8 |
7 |
标逗号的“读”(表示:语气上的停顿) |
逗号 |
逗号 |
|
9 |
8 |
标句号的“句”(表示:语义上的停顿) |
句号 |
句号 |
公式1
∑aijxj=bi 等价于:一组“字符多项式”[7],即:A={∑ n i x i }
或等价于:一系列“字组数据表”,即:与图2所述的系列“字组”表对应。
八、参考文献
1、徐通锵《基础语言学教程》2001年2月北京大学出版社,19-36页,178-237页[M]
2、北京大学计算语言学研究所《计算语言学文集》第4集“汉语语法研究所面临的挑战(98现代汉语语法学国际学术会议第一次全体大会宣读)”2000年12月,1-19页[C]
3、徐通锵《语言论--语义型语言的结构原理和研究方法》1997年10月东北师范大学出版社,295-442页[M]
4、邹晓辉“语言及语义信息的统一参照系(2000年12月)光明网论文发表交流中心转载
http://www.gmw.cn/03pindao/lunwen/show.asp?id=2321[EB]
5、邹晓辉“协同智能计算语言数据库的设计方法(2002年11月)--支持语言文字系统工程与全球语言定位系统的一个实施例”光明网论文发表交流中心转载
http://www.gmw.cn/03pindao/lunwen/show.asp?id=2274[EB]
6、《第五届(国际)汉语词汇语义学研讨会论文集》“义项语汇典例(SVDE)的总量控制模型(2004年6月) --人机协作对采用汉语注释的语义词汇典例进行计量分析”光明网论文发表交流中心转载
http://www.gmw.cn/03pindao/lunwen/show.asp?id=2271[EB] http://zxhrzx.blogchina.com[EB]
7、张学文《组成论》附录1“字符多项式与表格数学”中国科学技术大学出版社2003年12,44-56页,246-252页[M]
http://potentialscience.org/[EB]
九、致谢
北京大学中文系基础语言学教研室徐通锵教授与洛阳外国语学院计算语言学教研室易绵竹教授在百忙中阅读了本文的初稿,前者从基础语言学专家读者的角度给予了作者珍贵的提示,后者从计算语言学专家读者的角度给予了作者宝贵的鼓励,在此作者向他们表示真诚的谢意!
同时,还要感谢作者的母亲和妻子给予的关怀和帮助!
没有上述各位的关心和帮助,此文难以在如此短的时间内修订完稿,并与汉语“字本位”理论专题研讨会的各位专家见面(指:论文公开)。希望它能起到“抛砖引玉”的作用!
最后,还要感谢汉语“字本位”理论专题研讨会组委会提供这次机会!特别要感谢汉语“字本位”理论创立者徐通锵教授给本文提供汇编进入论文集的机会!
THE DEFINITION IN SYSTEM OF FORM ON CHINESE WORD
――ON GROUNDWORK FOR THEORY OF WORD(CHARACTER) AS ESSENTIAL UNIT
ZOU XIAO HUI
BEAUTIFUL-GARDEN BUILDING 15-2 NUMBER 201 IN ZHU-HAI 519125
Abstract
It is the main idea of this paper that THE DEFINITION IN SYSTEM OF FORM ON CHINESE WORD has been limited by GTCM or GSCM.GTCM means GROSS TEXT CONTROL MODEL. GSCM means GROSS SYLLABLE CONTROL MODEL. As CA( COMPUTER AID), GTCM or GSCM,can be used in computers and internet mathematically for helping users on learning Chinese and MT(MACHINERY TRANSLATION),at the same time, can also establish the definition in system of form on Chinese word for the whole language as root for tree or as foundation for building.
Keywords
WORD (CHARACTER) AS ESSENTIAL UNIT, LINEAR STRUCTURE(WORDS GROUP), THE DEFINITION IN SYSTEM OF FORM ON WORD(CHARACTER)