����������Ϣ��ʽ�����㷨�Ļ���õıȽ�
����ָ����������-��ũ����ľ�����Ϣ��ʽ�ǻ��㷨
(ǿ����������Ϣ��������Ļ�����Ϣ��ʽ�Ǻ��㷨)
�������������о����� ��˳���������ѧԺ��
�㶫�麣�����Ŷ�������15-2��201�� 519125
e-mail��qhkjy@yahoo.com.cn
ժҪ��Ϊʲô˵������-��ũ����ʽ��Ϣ��ʽ�ǻ��㷨����������Ϣ��������Ļ�����Ϣ��ʽ�Ǻ��㷨��ָ��ǰ���ǻ��㷨��ǿ�������Ǻ��㷨���б�Ҫ�𣿱������ȴ���ѧ�ϻش��˵�һ�����⣬���ţ�����Ϣ��ѧ���������ݴ��������ǶȻش��˵ڶ������⡣��ũ��Ϣ���������ģ�����������֪�ģ����ǣ�����������ľ�����Ϣ����������ʽ����ũ��Ϣ�۵Ļ�������������ͨ��רҵ�������ʿ��������ġ�ͬ����������-��ũ����ʽ��Ϣ��ʽ�����ռ�����Ҳ��ѧ���Ͽɵģ����ǣ��û�����ʽ�ǻ��㷨��ȴ����������ѧרҵ�������ʿ�����ӵġ�������߲�����������������֪ʶҪ�㣬��ô��Ҳ�ͱ�Ȼ��ʶ����������Ϣ�������������Ϣ��ʽ�����ü�����Ҫ�ԡ�
�ؼ��ʣ���������Ϣ ��ũ��Ϣ�� ���㷨 ���㷨 ������Ϣ��ʽ
BAD OR GOOD FOR THE ARITHMETIC OF INFORMATION FORMULAS
����POINTING OUT:HARTLEY-SHANNON��S INFORMATION FORMULA IS A BAD ARITHMETIC
FOCUSING ON: ZOU��S FORMULA IN GENERAL INFORMATION SCIENCE IS A GOOD ONE
ZouShunPeng ZouXiaoHui
ETERNAL BEAUTIFUL-GARDEN BUILDING 15-2 ROOM 201 IN ZHU-HAI 519125
e-mail��qhkjy@yahoo.com.cn
Abstract: Why we say that Hartley-Shannon��s Information Formula is a bad arithmetic,while ZouXiaoHui��s a good one? Is it necessary to point out that the former is bad and the latter is good ? We answer the first question based on mathemtics and then the second question based on information science and computer data processing.Shannon��s Information Theory is well-known,but people who are not in the domain of communication specialty do not understand that Hartley��s Information Formula is the foundation. In the same way, Hartley-Shannon��s Information Formula has been coming to light in the domain of the communication and computer science,but people who are not in the domain of mathemtics specialty do not understand that Hartley-Shannon��s Information Formula is a bad arithmetic.If readers did not understand the two key points,they could not understand the use or the fundamentality of ZouXiaoHui��s Semantic Information Formula in General Information Science.
Keywords: Hartley��s Information Shannon��s Information Theory Bad Arithmetic Good Arithmetic Semantic Information Formula
1.����
1.1.������̽�ֹ�����-��ũ�������ʽ��Ϣ��ʽ��������Ϣ��������Ļ�����Ϣ��ʽ����ƣ�������Ϣ��ʽ���Ĺ�ϵ������I = H - 0 = N log S����������ָ��-��������Ϣ��ʽ����I = Hs��p1����������pn��- 0 = ��K��pilogpi����ũ������-���ʡ���Ϣ��ʽ����I = D - 0 = m n�������ԡ���Ȼ��-������Ϣ��ʽ�� I = D �C K��K = 0��������֪ʶ������ʱ�����������������ϵ����H = Dʱ����������Ϣ��ѧ�Ļ��������о������漰��ѧ��ͨ�źͼ������ѧ�Ľ����о���
1.2.�����ԣ����Ĵ�������Ϣ��ʽ�Ķ����ӽǣ��������ط�����Ϣ����Ϣ��ѧ�ĺ��ĸ�����ں����䱾�ʺ����ӣ��������ģ�����漰����˫�б��ļ����ʽ����������λ���ʽ��������㷨��ѡ����
1.3.��Ҫ�ԣ����IJ�����ע��Ϣ�۵Ļ������⡪����Ϣ����Ϣ���Ĺ�ϵ������ָ�������Ե������������⣺a��Ϣ����ԭ����������Ϣ��ʽ����λ���ʽ����b�����㷨�û��ı���
1.4.�о�;�������ȣ���ս�Բ��棬ֱ�Ӳ�����������ģ�ͺ�������Ϣ��ʽ����ȷ��Ϣ���ں����䱾�ʺ�������ȷ�����Է����Ļ��������ţ��ڲ��Բ��棬��������˫�б��ļ����ʽ���������ȿ��ð˴���ʽ��ϵ����λ���ֿ�ʹ��Ȼ�˵Ķ��Է����ó��������Ķ��������س�����������������á������ս�����棬��ȷ֪ʶ��Ϣ���ݵ���λ���ʽ������m1 n1 + m2 n2 = m n����ȷ�����������Ļ��������Ƚ������ֶԸ�ָ�������Ļ���˼·����(��Nyquist���飬Hartley����Shannon���á���������������ʹ��)������(�����Բ���)��������Ϲ�ϵ���ݿ⣬������ѡ���÷ֲ����������Դ������̼����Թ滮���ֳɵĺ��㷨�ܷ��㣬���һ���ֱ��ʹ����Ȼ�������������㣩��
1.5.�����ԣ�һ��������-��ũ����ʽ��Ϣ��ʽ�ľ����ԣ����������㷨�û�������ԡ��˽��������������أ�������ȷ����������Ϣ��ʽӦ�õľ�������������
1.6.�������裺�㷨�ĺ��뻵�Լ��㷨�ļ��븴�ӵ�ȫ���ж��Ⱦֲ��ж�����Ҫ��Ҳ����˵������˵��ʽ��Ϣ��ʽ�ǻ��㷨��������Ϣ��ʽ�Ǻ��㷨��ȫ���жϡ�
1.7.���ף���һ��̽����������Ϣ��ʽ���ں����磺a��ȷ���֪ʶ��Ϣ���ݵ���λ���ʽ��b��ȷ�����Ϣ������ʽ��������ʽ�������û����ӣ��Ŀ�ѧ���б�����һ���ɼ��㣬�ڶ������㣬�����㷨�ã�Ҫô��Ч���㹻��Ҫô�临�ӵ��dz���Ч�Ҿ��ʵ������ɻ���Ϊ��c��ȷָ������˫�б��ļ����ʽ�������������ʵʩ������ѧ��ͨ�źͼ������ѧ�����ݡ�
2.����
����֪������ѧ����Ϣ�������ѧ����ԨԴ���ִ�ͨ�ż���ʵ����ӵ�й�ͬ��ͨ�ŷ��Ŵ�������磺��ĸ����Ħ��˹���롢ASCII��Unicode����˫��������ͨ�ŵĻ��������ڸ�����ξ������������ɹ��Ϊ�������㷨��ѡ���������ǰ������Ϣ���۵������ߣ������������������Ϣ�����Ϣ����ʽ��ͬʱ���������̽�ֵ����⡣
2.1.��������Hartley1928���������Ϣ�������Ϣ����ʽ
����1����Ϣ������ͨ�ŷ��ű��У�ѡ��ͨ�ŷ��ŵķ�ʽ������2��ѡ������ɶ�[S��N�η������У�S��ʾ���ű��з��ŵĸ�����N��ʾ��ѡ�������еij��ȣ�]������������Ϣ���Ĵ�С����ʽ1��I = N log S ��ʽ2��H = N log S [I��H����ʾ��Ϣ��NlogS��ָ������S��N�η���ȡ��������ʽ]��
������˼��������1a��ѡ��ͨ�ŷ��ŵķ�ʽ����ζ��ʲô������1b��ѡ������ɶȡ�����ζ��ʲô������2a��ͨ�ŷ��ű�������S��N�η�����ζ��ʲô������2b��ʽ1��2��ʲô��ϵ������1������������ģ�Ϳ�������1a�漰�����������������룩��������ѡ�����⣩�������š����ģ�������ʽ�����壩��һ�����ϸ��������ѡ��ʽ�������壩��һ�����Ӹ��������ͨ�š������У���ͨ��������������ܵ�ת���������š�[��������Ϣ��=���⡢�ġ��壩]������1b�漰�������ɶȡ�[��ѡ��ķ�Χ����������⡢�ġ��壩]������2������2a�漰�������ű���[˫���������������ѡ��Ĺ�ͬ���ݻ��]�����������š����ģ�����������������־����ϵ����λ���壩����S��N�η�������ʾ��Ϣ������ָ���������磺���п��ܱ�ѡ���״̬������������Ϣ��ʽ��������2b�漰��D = H����ʽ1��2��Ŧ����K = 0 ������������֪ʶ�����壩������1����ȫ���Ͽ������ڷ��ű����������ˡ��������������������ˣ�ͨ�Ž�����������ǰ�1���㷨�ĺ��뻵���磺����������ָ��������2���㷨�ļ��븴�ӣ��磺������С��������2����ʽ1��2�Ĺ�ϵ������I = H - 0 = N log S ��
2.2.��ũ��Shannon,1948��������Ϣ����Ľ�����Ϣ����ʽ
����3����Ϣ������������������ԵĶ���������4����Ϣ������������Գ̶ȵļ��١���ʽ3��I = Hs��p1 ����������pn��- 0 ����ʽ4��Hs��p1 ����������pn��= ��K��pilogpi ��
������˼��������3������������ԡ���ζ��ʲô������4���������Գ̶ȡ���ζ��ʲô������3������3�漰������������ʣ����������ԡ��������ԣ�������4������4�漰�������Գ̶ȡ�������̶ȣ�������3������������ʹ��������ϸ������������Ҳû�иı䱻ȡ������ʽ������ڸǵ�ָ����ʽ������4���ж��������Ƕ��Է�������������̶��Ƕ�����������ע�������-��ũ����ʽ��Ϣ��ʽ����������ϵ�Լ����ǵľ����ԣ��ظ�˼·�ƹ�ĺ����ߴӸ���Ҳ������Լ��
2.3.��������ZouXiaoHui,1997����չ����Ϣ�����������Ϣ���ʼ�������Ϣ��ʽ
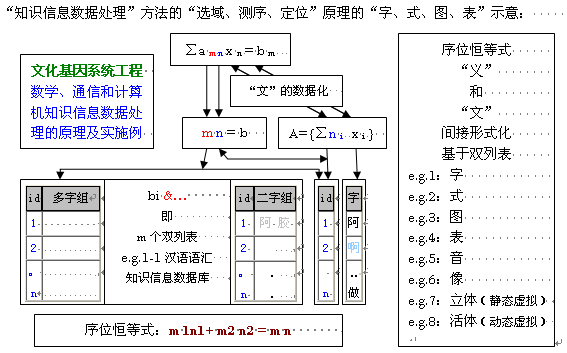
����5����Ϣ���ں����漰�������ͣ�ʱ����λ��������λ��������λ��������λ����Ϣ��������λ����������������Ϣ������Ϣ�����ӣ��漰���������������룺����������ʶ�����磺֪ʶ���������������������磺�ı����ﻯ����������Ϊ��������������������λ���壬�磺��ϵ���ݿ��б�����λ������ʽ��Ϣ����ѡ��λ��ʶ��������Ϣ�������ж��漰��Ϣ��֪ʶ�Ĺ�ϵ������6����Ϣ�����ɲ���λ�����㡣��ʽ��Ϣ�����������漰��Ϣ�����ݵĹ�ϵ����ʽ5��������Ϣ��ʽ��I = D �C K ��������Ȼ�˻������û���������Ϣ����ZouXiaoHui,1997-2005����ʽ6����ʽ��Ϣ��ʽ��I = D - 0 = m n�����ڼ��������ʽ��Ϣ�����ݼ���D = m n ZouXiaoHui,1997-2005��
����˼��������5������λ���塱��ʲô������6�����ʵ�����ݡ���Ϣ��֪ʶ��ͳһ����������5������5�漰������Ŀ����ģ�����λ��������6������6�漰�������ʽ���ģ������ݡ���Ϣ��֪ʶ��������5����������Ŀ����������Ŀ������˫����ͨ�Ż���������ȷ���Ի���֮���������֮�оݣ���ͨ˼֮��·������˼֮�������ұ��ڵõ�������������������� ����6����˫�б��ķ�ʽ�����ʽ��������[�磺�˴���ʽ�������֡�ʽ��ͼ���������������塪����̬���⡢���塪����̬���⣩֮һ�ľ�����ʽ���磺���Ļ�Ӣ�ģ���������Ŀ��������ݣ��ȿ���δ֪�����ݡ�����Ϣ��Ҳ������֪�����ݡ���֪ʶ]������δ֪��I����֪��K��ɵ�Ŀ����D��m��n�еľ���m n������ѡ����λ������˫�б��ļ����ʽ����m n = I + K������
2.4.��������������һ��̽�ֵ����⣩
����7��Ϊʲô˵������-��ũ����ʽ��Ϣ��ʽ�ǻ��㷨����������Ϣ��ʽ��ע����ʽ6�ǹ�ʽ5���������Ǻ��㷨��������ʽ1��2��3��4��5��6֮����ʲô��ϵ������8��ָ��������-��ũ����ʽ��Ϣ��ʽ�ǻ��㷨��ǿ�����幫ʽ�Ǻ��㷨���б�Ҫ�𣿼�����ָ��ȡ������һֱ��;��֮�⣬�����������;�����Ի�ø��õ��㷨��
���������7������8�ķ�����ּ��Ѱ����;�����ͽ����ּ�ڿ�����;������ʽ����ȫ��˼·��
3.��������
3.1.�����㷨��˼·�ıȽ�
���ȴ���ѧ�Ͻ������7�����ţ�����ѧ��ͨ�����������ݴ����ĽǶȽ������8��
��ʽ1-4��ʽ5-6�ֱ��ʾ��Ϣ����������ֲ�ͬ˼·��ͬ���Ǽ�����Ϣ������ʽ1-4���á�ָ��-��������������-���ʡ��IJ��������ر�ֱ�Ӽ���ܴ����Ȼ������ʵ�������⣩������ʽ5-6����á���Ȼ��-���IJ������ɼ�Ӽ���ʵ���ҿɰѺܴ����Ȼ���ֽ�Ϊ�൱С֮���ټ��㣩��
����H = D���ҡ�K = 0��ʱ����I = H - 0�� ����I = Hs��p1 ����������pn��- 0���롰I = D - 0���ȼ��Ҿ�Ϊ��I = D �C K������������ʽ6��ʾ��Ϣ��������������λ������������ֻ����������ʽ�������dz����������磺֪ʶ�����壩����Ϣ������������Ϣ�ص�������
��H = N log S������Hs��p1 ����������pn��= ��K��pilogpi���롰D = m n���ǶԸ�ָ���������磺S��N�η��������ֻ���˼·���漰��(Nyquist and Hartley����)������(Shannon����)���ʡ�(Zou Xiao Hui����)��������ѡ���÷ֲ����������Դ������̼����Թ滮���ֳɵĺ��㷨Ҳ�ܷ��㣩�����㷨���ͣ����У�ǰ��������ָ��-�������͡�����-���ʡ������ڡ��ⳬԽ���̵����͡����һ��������Ȼ��-�������ڡ������Է��̣��飩�����͡�֮����ڻ���õ�����������֪��������ָ���Ǻ����뷴�����Ĺ�ϵ��������ɼ��㣬ȴ���ܸı���Ҫ���������������ָ�����������ʡ���ˣ�ǰ���ֻ����㷨���ɹ��Ϊ������ָ���Ķ�����ֵ���㣬�������μ�������������Ӵ��ң�û����֪ʶ��Ϣ���ݴ����Խӵ���ʽ��;������һ���㷨��ɹ��Ϊ��������Ȼ�����������ּ��㣬������˫�б��ļ����ʽ����������������֪ʶ��Ϣ���ݴ����Խӵ���ʽ��;�������ң����������������ķ�ʽ���Ƶģ���֮�������Ѱѳ�ָ�����������ݷֽⲢת������Ӧ�л��е�����������ʽ����˸��μ������Ȼ�����ֵ��������൱���ƣ�������½����������ּ��㣬��������»���ֱ�����ø��������㷨���ܺ���ѡ�á�����ѡ�š��ɴ˿ɼ�����ӳ�����㷨�����ֻ���˼·��Ƚϣ���һ��˼·���㷨�ϵ���Խ�����Զ����ġ���Ȼ��ˣ�Ϊʲô���ǻ�Ҫ����ǰһ��˼·��������㷨�;����㷨��·�������������أ�һ����Ϊ�����������Ժͳ���ļ����Ե���Ҫ��������Ϊ�¾����ֻ���˼·�ĶԽӻ�ת��Ҳ��һ��ĥ�ϵĹ��̡�
���ڿ���������Ĺؼ�����������Ϊ����˼·��ѡ��������������Ϣ��֪ʶ����ʾ����ʽ��;���ϲ�ͬ�����ң�����Ϊ֧�ָ���˼·����Ϣ�ۼ�������Ҳ�и���������
3.2. ȫ�µ�˼·�ͷ���
���ȣ���ȫ�ֿ��ǣ���ս�Բ��棬ֱ�Ӳ�����������ģ�ͺ�������Ϣ��ʽ����ȷ��Ϣ������ں����䱾�ʺ���������������2.����2.3.����5����ȷ�����Է����Ļ�����
���ţ��ڲ��Բ��棬��������˫�б��ļ����ʽ���������ȿ��ð˴���ʽ��ϵ����λ���ֿ�ʹ��Ȼ�˵Ķ��Է����ó��������Ķ��������س�����������������á�
�����ս�����棬��ȷ֪ʶ��Ϣ���ݵ���λ���ʽ��������һ����Ⱥ�ı���ʽK + I = D ��������Ⱥ�ı���ʽm1 n1 = K �� m2 n2 = I �� m n = D ����϶�����һ�����ı���ʽm1 n1 + m2 n2 = m n����ȷ�����������Ļ�����
4.��ʾ
4.1.��ѧ˼��
����֪��������������ָ������������ѧ���Ƿdz����������ּ���ģʽ���Ӹ�����˵���㷨�û��Ի��ڴˡ�ͨ������£�����֮����ڲ�����Խ�ĺ蹵�����������ѧ˼ά����ȷ�����ҵ��ȶ����ٺõķ������Ը�ָ���������ο�������ϰ���ߡ�ָ��-������ת������·����ȻҲ֪���������Ƿdz���Ч����ѧ���ߣ��ر����ڼ��������������¡�����������֮���ƺ�û����ͨ��·������ˣ��ܷ��֡�����˫�б��ļ����ʽ������������Ϊ��ġ����������ݾ����ͳ��ˡ�Ѱ�Һ÷��������㷨���Ĺؼ�֮���ڡ�
4.2.��Ϣ��ѧ˼�����漰����һ������ѧ˼������������Ϊ��Ĺؼ�����Ϣ����ԭ��
��������ѧ�����������������������ּ������ַ�����ʽ��ͼ��������������������̬���⣩����������̬���⣩���˴���ʽ��ϵ�Ĺ����ı�����Կ�������ȫ��ƽ�в�ʽԪ�ء�����������Ȥ����������������ײ�ʽ��Ա�������ơ������ȫ����ԭ�͡�ͬ�岢�ж�Ӧת���������롰�ռ�����Ϣ�����롱��Z-ASCII���ı���������ϵ����GTCM���ı���������ģ�ͣ���GSCM��������������ģ�ͣ�����ı��ġ�Ӧ�Բ���ϵ����һ�Ļ�����ϵͳ���̵�������֮�С�
4.2.1.��ȫ��ƽ�в�ʽ�����ӡ�����Ȼ���ķdz�����
�ɸ�λ��һλ����ΪԪ�ض����ɵĶ��������ļ��ϣ�����0��1����Ԫ�أ���ʮ�������ļ��ϣ�����1,2,3,4,5,6,7,8,9��0ʮ��Ԫ�أ�����ȫ���������Ϊ�����ƽ�в�ʽ������Ȼ���������dz��������乲ͬ���ص㣺һ��Ԫ�ظ����dz����ޣ����ǹ���Ԫ������Ҳ��������ȫ��
4.2.2.��������ײ�ʽ�����ӡ�����Ȼ�������ޱ任��
����{0,1}��{0,1,2,3,4,5,6,7,8,9}��Ԫ�ض���ɵ���������dz�����Ķ�����ײ�ʽ�����Ա��һ������������λ���ֹ��ɣ�������Ȼ�������ޱ任�������ڿɼ����ҿɽ��ܵķ�Χ�����乲ͬ�ص㣺һ��Ԫ�ر����õĴ����ࡢƵ�ʸߣ���������Ԫ��λ�������ӻ������Ӧ�Ľ��ײ�ʽ���磺����λ������λ����������λ�����ɵ�1��2������m���ײ�ʽ������ÿһ���ײ�ʽ��λ����ͬ�Ķ����Ա���������������ϣ�������ȫ�����Ϊ0���ײ�ʽ��
4.2.3.�������ӡ�����ȫ�����磺S���볬����[�磺S��N�η����漰�����ֻ���˼·�ıȽϣ�]
���ֻ���˼·�����㷨���ͣ���ת�����踴�ӱ任����νֱ�Ӽ������������ڡ�ָ��-�������ij�Խ�����㣬�磺����S��N�η���ΪNlogS�ԶԸ���ָ����ը�����븴��ת����ֻ��任����ν��Ӽ��� [�������ڡ���Ȼ��-������Ȼ�����㣬�磺�����ڡ���Ȼ�������ޱ任������������S��N�η������ҡ�N������ת��Ϊ��m�����ײ�ʽ��n����Ա�����Ӷ����ɸ���Ч�ضԸ���ָ����ը��]��
4.3.��������ݴ�����������Ӧ��ʵ����������Ϣ�����Ļ����ṹ����ģ�ͣ�
��m n��ʾ���ײ�ʽ�����Ա���������ȿɺ�һ���磺ASCII��Ҳ�ɷֱ����磺���������ļ�����ʮ�������ļ��ϣ�������λ�㶨����ȫ��ƽ�в�ʽԪ��һ������������ȫ��m0�Ķ��ƽ�в�ʽһ����������Ԫ��n0�Ķ�����������ASCII��һ����չ��Z-ASCII���磺���Ӻ��ֱʻ���һ�����ƽ�в�ʽ������ô���� m0 n0����ɽ�������˫�б��ļ����ʽ��Ԫ�ط���ģʽ�Զ�ʶ��Ļ�����ϵ����������ȫ�����ƽ�в�ʽ����Ԫ�ع��ɵ����ݼ��ϣ��磺Z-ASCII����Ϊ��������ײ�ʽ����Ա���������Ļ�����Ҳ����˵��ͨ�����ɡ��ɼ����ȶԡ�ת���ȷ�ʽ�����ɽ�һ����������Z-ASCII����λ�㶨�ij�������ײ�ʽ��Աһ����������m�����ײ�ʽһ���������г�Աm n�Ķ�������磺GTCM��0-6���ײ�ʽ��Ա��ϸ����ʽ���� m n����ɽ�������˫�б��ļ����ʽ����Ϸ���ģʽ�Զ�ʶ���Ӧ�Բ���ϵ�������ɳ���������ײ�ʽ����Ա���ɵ����ݼ��ϣ���Ϊѡ��������ȷ��m��ֵ����λ������ȷ��n��ֵ���Ķ�����������������ȷ��m��n��ֵ�������ּ������ݡ��ٽ�һ������m n��ѡ����֪��������m1 n1����Ϊ����֪ʶ����λ���ϣ�������δ֪��������m2 n2����Ϊ������Ϣ����λ���ϣ����������ڡ�m1 n1 + m2 n2 = m n����˫�б������ʽ��֪ʶ��Ϣ���ݿ�ɹ��ɣ���������Ի���ϵ�һϵ�о����ͨ�ú�ר�ü���ƽ̨��GTCM��0-6���ײ�ʽ�ǵ��͵�Ӧ��ʵ�������У�������Ϣ��������GTCM��0-4���ײ�ʽ���ּ���Ϣ��������GTCM��4-6���ײ�ʽ[���йع�����̣���������Ϣ�����ļ����ʽ���·���������ܡ������ο����ף�������Ϣ��������GTCM��7-12��7-15���ײ�ʽ�����ο����ף����IJ����ۣ�]���������ģ�ͣ�������Ϣ�������ı��ṹ����ģ��[STCM in word������GTCM��0-4���ײ�ʽ��]�������Աʻ�Ϊ������λ����STCM�����ڵIJ����ͽṹ1-m ϸ�ֽ��ײ�ʽ����Ӣ������ĸΪ������λ����STCM�����ڵ��ߴ��ͽṹ1-m ϸ�ֽ��ײ�ʽ�����ּ���Ϣ���������ڽṹ����ģ��[SSCM between words������GTCM��4-6���ײ�ʽ��]: ��������Ϊ������λ����SSCM������������ߴ��ͽṹ1-m ϸ�ֽ��ײ�ʽ����Ӣ���Դ�Ϊ������λ����SSCM���ʺʹ���������ߴ��ͽṹ1-m ϸ�ֽ��ײ�ʽ����
5.����
5.1.���ۣ���֪ʶ��Ϣ���ݴ����ļ����ʽ���������ԣ���λ���ʽ�ķ��֣�Ϊ������Ϣ���۴�ȫ�ֵ��ֲ���ѡ���㷨�춨����ѧ��ͨ�źͼ������ѧ�ļ�ʵ������
����λ���ʽ���͡���Ϣ������ʽ���Լ��������ʽ����������ϣ���������ѧ�ϵ���Խ�Կ��Է��ӵ����쾡�£����ң���֪ʶ��Ϣ���ݴ����ϵ���Խ��Ҳ�ɷ��ӵ����쾡�¡����ԣ���������ѧ����ѧ��ͨ�����������ݴ�������ϵĽǶȷ����ˣ��Ѽ���������ʽ�ֽ�֮��ת��Ϊ������������;������������������D�ֽ�Ϊ����m n �����ٰ�m��n������ת��Ϊ��Ȼ�����������㷽�����������ˣ�ȫ���㷨��ָ����ʽ�������ľ�;���뼸��������ʽ����������;����������ֲ���������Ϣ�صĸ��ʷ�������Ϣ���ķֲ������������������ϵ��
5.2.�ܽ���IJ��ù�������ѧ�Ĺ۵����ѧ��ͨ�����������ݴ�������������������ʽ��Ϣ��ʽ��������Ϣ��ʽ�Ĺ�ϵ����������ѧ����ȷ���鹫ʽ�ı������壩���磺S��N�η�������D�ȿ�ֱ��ת��ΪNlogSҲ�ɼ��ת��Ϊm n�������ֱ�ʾ������ȣ��㷨���졣��ʽ��Ϣ��ʽ��ѭ����ָ�������ķ��������������;����������Ϣ��ʽ��ѭ�������������ķ����������;������ͨ������ȷ���鹫ʽ���������⣩���磺ͨ�ŵķ��ű������ݽṹ��ͬ��ѡ���Ч�ʵ�ȻҲ�Ͳ�ͬ����ʽ��Ϣ��ʽҪ��ͨ��˫��������ӳ�ָ��������һ�����ݱ�������ѡ��������Ϣ��ʽҪ��ͨ��˫��������ӳ����������Ķ�����ݱ�������ѡ�Ӽ�������ݴ�������ȷ���鹫ʽ���ı����ģ����磺���ݽṹ��ͬ����ѯ·���ͼ���Ч��Ҳ��ͬ����ʽ��Ϣ��ʽҪ���ı�������ֱ����ʽ����������Ϣ��ʽҪ���ı������ݼ����ʽ����
5.3.���ۣ����㷨�ص��Ǽ���������ָ���������磺S��N�η���������̫���ʧ�����磺С�����и�����������ֱ�Ӽ�����������ָ�����������㷨�任������ϼ������磺���ӵ��ַ����������㷨�ص��������������磺N�������ɽ�һ���ֽ�Ϊm�������ɿصĽ��ײ�ʽ���磺����������������������Ӽ�����������ָ���������ļ�ӱ任�����ֽ�������磺��һ���ַ�������������Ŀ�����һ��˫�б��������ִ�����ɾ�����Ϊ�����ʽ����������ѧ���������У����б������������һһ��Ӧ��D��I��K��m n�е���λ��һ�µģ�����{���б�ż���} = {�������ݼ���}�����������ڣ�����Ŀ����D��m��n�����ִ��빹�ɣ�����D = m n ��m n = D = I + K����Ϣ������ʽ������ʽ������Ϣ������ʽ������ʽ�����л�ͳһ���������ݼ�����Ҫ��������ʽ��ݸ�Ч�����˻�����ϵ��Ӧ�Բ���ϵ�ĸ����ѧ��ʽ������ģ�ͣ���GTCM��0������GTCM��0-6����֮�䣬����ͨ�������ʽ���ķ�ʽ�������������������Ϣ������ʽ��ʵ�ּ�Ӽ����ֱ�ӳ��֡��ؼ���������Ϣ�ı��ʡ���Ȼ�˶��㷨��ѡ��Ӱ�������ľ��崦����ʽ���ڲ�ͬ�������ļ���N={��}�У������Ը�λ��һλ����ΪԪ�ض����ɵļ���֮�⣬��������λ������λ����������λ��Ϊ��Ա�����ɵļ��ϣ���ǰ�������ϵ��ֵ�ý�һ��̽�ֵġ�ͬ����ASCII��Z-ASCII��Unicode��GTCM��0-6����֮��Ĺ�ϵ��Ҳֵ�ý�һ��̽�֡�
�����
R.V.L.Hartley��Transmission of Information [J] BSTJ,1928 Vol.7
Claude E.Shannon and W.Weaver��Mathematical Theory of Communication [J] BSTJ,1948 Vol.27
N.J.A.Sloane and A.D.Wyner��Shannon,C.E Collected Papers [C] IEEE Computer Society Press1993
�����ţ���Ϣ��ѧԭ��[M]�����ʵ��ѧ������1996
Losee, R. M.��A Discipline Independent Definition of Information [M],Journal of the ASIS 1997,
�����ԣ�һ��֪ʶ��Ϣ���ݴ�����������Ʒ[J]������֪ʶ��Ȩ������ 2000
�����ԣ�Эͬ���ܼ����������ݿ����Ʒ���[J]DZ��ѧ����32�ڣ�2004��7���Ա����廪�Ƚ���2002
�����ԣ�Эͬ���ܼ���֪ʶ���ݿ����Ʒ���[J]DZ��ѧ����39�ڣ�2005��1�����п�Ժ���廪����2002
��ѧ�ģ������[M] 44-56ҳ��246-252ҳ���й���ѧ������ѧ������2003
Zou Xiao Hui�������ԣ���The Gross Control Model of Semantic Vocabulary as Dictionary with Examples[A]Recent Advancement In Chinese Lexical Semantics [A] CLSW-5 [C] Singapore,2004
�����ԣ��ع������������ϵ������˼·���·�������������������ģ������[A] CLSW-6 [C] ���Ŵ�ѧ2005
�����ԣ��Ż���������Ϣ���������·�����ʵʩ���������������ʽ����������[A] CLSW-6 [C] ���Ŵ�ѧ2005
�����ԣ�������Ϣ�������·����������������ʽ����JSCL-2005)[J]DZ��ѧ����42�ڣ�2005��4��
�����ԣ���Ĭ��ͨ����������Ӽ�����������Ȼ���Դ���������Ҫ��[J]DZ��ѧ����42�ڣ�2005��4��
�����ԣ�������Ϣ��������������Ϣ������ʽ����[J]DZ��ѧ����43�ڣ�2005��5��