������Ϣ�������·���
������
0756-5505041 qhkjy@yahoo.com.cn 519125 �㶫ʡ�麣�о����Ŷ�������15-2��201��
ժҪ��Ϊʵ����Ȼ�������������ƻ�����ͨ���˻��ֹ�Э���������ṩ��������Ϣ�������·�������Ҫ�漰���ı���������ģ���������й�����Ϣ���������͡�������������ģ������
�ؼ��ʣ��������ݿ⡢֪ʶ���ݿ⡢�����ʽ����������Ϣ����
NEW METHOD OF CHINESE INFORMATION PROCESSING
ZOU XIAO HUI
0756-5505041 qhkjy@yahoo.com.cn BEAUTIFUL-GARDEN BUILDING 15-2 NUMBER 201 IN ZHU-HAI IN CHINA 519125
Abstract��We offer the new method of Chinese Information Processing that user cooperates with computer for interpenetration. It mainly relates to GTCM, Z-ASCII and GSCM.
Keywords��Language Database, Knowledge Database, Indirect Formalization, Chinese Information Processing
����
�����漰��֪ʶ��ʾ�����Ͽ�����ѧ������ģ�͡�����ѧϰ��֪ʶ��ȡ�����������ȣ����ڼ�������ѧ�����о��������ص��ǣ����á������ʽ����������ֱ�ӽ��С�������Ϣ�����������ص��ǣ�ͨ����Ȼ��������֮��ķֹ�Э����ʵ�����ƻ������о�;������������ϵ���ݿ⡱����ʽ���漰��ǰ̨���桢��̨�����Լ�ǰ��̨����ת����ʵ�֡������ͣ����֡��롰���ַ��������֡��ġ�ͬ�岢�С��ﵽ���˻�Э�������ƻ�������Ŀ�ġ�������ǣ��˻�Э���������ݹ�ͬ�ġ�����ϵ�����������裺���ڡ���ϵ���ݿ⡱��ʵ�ֵġ����֡��롰���֡��ġ�ͬ�岢�С�Ϊ�˻�Э���ṩ������������ϵ������ʵ���ɷ����Ե�������Ϣ����ת��Ϊ���Ե�������Ϣ���������ݡ�֪ʶ���ף���������Ȼ���Դ����ҵ���һ������ĸ��ġ������ʽ�������������磺ʹ�����Ե�������Ϣ����ת��Ϊ���Ե�������Ϣ���������ң�Ϊ���������ܡ��롰�˹����ܡ�֮������ġ�Эͬ���ܡ��ṩ��һ������ʵ��������������ġ������ʽ����ʾ�������������ּ�����ͨ�еġ���ʽ������������Ӣ��ġ�����ּ�ӵ���ʽ��������ϣ�����Ľ��ܵġ�������Ϣ�������·������ܸ�ѧ��ͬ�������������ʾ��
����
������֪��ͨ�еĺ����ʽ����̽��һֱ����û��ͻ������һ�ָ�֣�
һ���棬��������û���Լ������ġ���ʽ���������������ò������ڻ���Ӣ��ġ���ʽ��������֮�ϡ���ͱ�Ȼ�������¼������⣺1�����֡���Ȼ���ԡ�֮��ġ����ɷ��롱���֣���Ȼ���һϵ�����������⡣2�����֡�˼ά��ʽ��֮��ġ��������𡱲��֣�����ͨ�������롱������硣ϰ�ߡ�����˼ά�����ˣ���ʹӢ�����յýϺã�Ҳ�����٣���˫���ͻ���⡣3����Ӣ�ﴦ�����Դ��ڡ���ʽ�������⡣Ŀǰ����ν����Ӣ��ġ���ʽ������ʵ�����ǻ���Ӣ����ĸ�ĸ����˹����Եġ���ʽ��������Ӣ����Ϣ���������衰�������ԡ�Ϊ���н顱���ܽ��С�4��Ŀǰ��ͨ�ü�����н������������������롱���͡������е���ν����ġ���ʽ����̽����������û���뿪������1��2��3�����ƣ������Ѻ�����Լ�̶��Dz��Զ����ġ�
��һ���棬����������ۣ�����û��һ������Ч������������ʵ���������ۻ������ܣ��ر��ǣ�����������ⳤ�����۲��ݶ��ò�������Ľ�����������ֽ�һ���������������⣺5����Ϊ��Ȼ�˵ĺ���ר�Ҷ��ֱ治��ġ��������硱������ü�������á�6����ʹ��Ϊ��Ȼ�˵ĺ���ר���ѷ���ġ��������硱����Ҳδȫ��ʵ�ּ�������á�
��ʵ֤���������ǻ����ִ����ġ����ż��������ǻ��ڡ���������Ϣ�����롱�ġ��ַ�����������������������γɵĸ��֡�������������ԡ������롰������ϵ����������˼ά��ʽ���͡������ַ�������ֱ��ԨԴ��ϵ������ѧ����е���ν����ġ���ʽ����̽����ʵ���ϣ���������Ӣ����һ�����һϵ�С��н����ԡ����磺����Ӣ��ĸ��ֳ������ԡ����˹����ԣ����䡰���ŷ������磺���ڳ������Ե���ʽ��������ν������ּ�ӵġ�����ּ�ӵ���ʽ�����������ѳ̶��ɴ�Ҳ�ɼ�һ�ߡ�
�ӷ������������������������һϵ�еij��ԡ��Ⱥ������������Ʒ�����һ������ͨ����ĸ����һ��֪ʶ��Ϣ���ݴ�����������Ʒ��Эͬ���ܼ����������ݿ����Ʒ�����Эͬ���ܼ���֪ʶ���ݿ����Ʒ�����������������SVDE������������ģ�ͣ��Ż���������Ϣ���������·�����ʵʩ������������������Ĺ�ϵ��̽����������ʽ������·��ʵ��֤��������ĸ��ġ������ʽ������������ʵ���еġ����ԡ�������Ϣ������Ϊ�������ܡ����������������£�
����
���Ľ��ܵ�������Ϣ�����·������漰���¼����������裺
1�����֡���ȫ���������͡����ײ�ʽ����
2����������ϵ���ݿ⡱��������������ģ�͡���
3�����֡��ı����͡����ڡ����ࡰ����ģ�͡���
4��������ģ��ʵ�ֺ���ġ�������������ע����
���������ڣ�
1�������ײ�ʽ�������ġ����֡��롰���֡��ǡ�ͬ�岢�С�һһ��Ӧ�Ĺ�ϵ����
2�������ײ�ʽ���ĸ�����һ���������и��ԡ�Ψһ�ı���mi��Ϊ�����д��롱��
3�������ײ�ʽ���ĸ�����һ�������еġ����������֡��ġ���λ��ͬ�岢�С���
4�����ۡ��ı������ǡ����ڡ��ĺ���ģ�͡���λ���루mi ,nj������Ψһ�ġ���
5����mi ,nj�����ɵġ������漰�����Է����顱���ָ�����֪�ġ����㷨����
6������������ѧģ�ͼ���ϵ���ݿ�����ʵ�ֻ���ĸ��ij�����ƺ��Զ����ã�
7�����֡���������Ĺ�ϵ���ġ����ֹ�ʽ���������С����ڡ��˻�Э�����硱��
���������漰�ĸ�����������ע����
���
����������Ϣ�����·�������ֱ�ӻ������������֡��ͺ�����֡�֮�����Էֹ�Э���ġ�����������ʽ��������������������Ҽ����ڣ�ֱ�ӻ������������֡���Ӣ���ĸ���ĸ��ֳ�������֮�����Էֹ�Э���ġ���Ӣ�����ּ�ӵ���ʽ����������ͬʱ��Ҳ����������Ҽ����ڣ����������ּ�ӵġ�����ּ�ӵ���ʽ����������
ʵʩ������Ϣ�����·�������������½����
1��������������ģ�͡�����A�⡱�����Ľ��������人�ﲿ�֣�
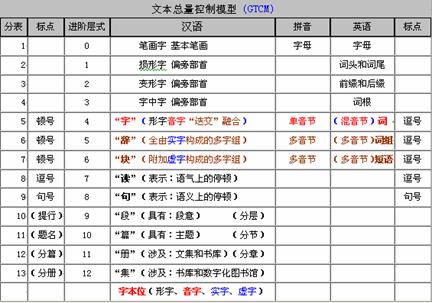
��GTCM��(���ı���������ģ�͡�������ͼ1) �ǡ���������������ײ�ʽ���ĺ�������ʽ������ϵ�����У��漰��������IJ��֣�һ���ǡ���ȫ������Z-ASCII�������й�����Ϣ�����롱��(����ͼ2)����һ���Ǵʻ�һ�����ַ���ģ�͡��IJ��С�ϸ����ģ�͡�������GSCM��(��������������ģ�͡�������ͼ3)���ԡ�������Ϣ���������ԣ����ݡ�������Ϣ�������ּ���Ϣ����������Ϣ������GTCM���ɷ�Ϊ�������顰һ������������m i���ֱ�ȡֵΪ��0-4��4-6��5-12���ɡ�GTCM���ġ�4-6�� ������һ�������ϲ�֮���ٰ����ֱ�λ�������Ϊ��GSCM����1- m������һ�����������ط������ּ���Ϣ�����ڴˣ���GTCM���ǹ���ġ�������ʽ����ģ�ͣ���GSCM��������ġ�������ʽ����ģ�͡�
2��֪ʶ��������ģ�͡�����B�⡱�����Ľ����漰�����֣�
���ڡ�A�⡱�ġ�B�⡱�ǰ�����ע���ķ�ʽ����������չΪ������Ϣ��ע���С������ɵġ�֪ʶ��Ϣ��ѯ�����ݿ⡣���ڱ����ġ�A�⡱�͡�B�⡱(����ͼ4)���û��ɽ������Ի���N�⡱(��������������ģ�͡�)��
ͼ1���ı���������ģ�����漰GTCM��0-12������ʾ��ͼ��ͼ2���й�����Ϣ��������Z-ASCII���漰GTCM��0-4�����еĵ�һ������ʾ��ͼ��ͼ3��������������ģ�����漰GSCM��1- m������ʾ��ͼ��ͼ4�ǻ��ڡ�A�⡱��GSCM������ע�����Ϊ��B�⡱ʾ��ͼ��������ͼ��
����
1��Z-ASCII�ɴ���������ײ㼼����ԭ����ʵ��ͻ��
ͨ��GTCM�ɹ������ں����Ҽ���Ӣ��ġ��й�����Ϣ�����롱����Z-ASCII���磺��Unicode�к��ֵġ������̶��ṹ����Ϊ�������ͻ�ṹ����ʵ�֡���ȫ���롰��������������ײ�ʽ��һ����֮����������ʽ���֣���ɺ��ֵġ�ģ����Ϣ��������������Ϣ��������ת����
2��GTCM��GSCM�ɴ������������֡����������塢������ã���Ϣ������ԭ����ʵ��ͻ��
�Ժ���ġ�GTCM������������4�����ײ�ʽ�������ڵġ��֡�Ϊ�������ṹ��λ������������5-8�����ײ�ʽ�������ڵġ����顱�����У���4-6�Σ��漰��GSCM�����ڣ��ʻ㼰�ʷ�һ���ġ���Ϣ����������7-8�Σ����ڣ����Ӽ��䷨һ���ġ���Ϣ��������Ҳ����˵����4-8�εĴ������ġ�Լ���������ġ���ʽ���ϡ������ˡ����������֡����������塢������ã���Ϣϵͳ����
3��GTCM��GSCM�ġ�������ʽ��ϵ���ŵ㣺�˻������ġ�ĸ�ﻯ��
�Ϳ�ʹ��ĸ���̶��ԣ����ڣ����ֳ������ԡ��磺��ͨ�û�Ҳ��ֱ��ʹ�ú������������������Ĺ��̣����൱�ڡ�ĸ�ﻯ����SQL���ṹ����ѯ���ԣ���XML������չ������ԣ��Լ��������ֳ��õij������ԣ��������ɡ�ĸ�ﻯ������ѧ����ֱ���ų����������ˡ��Ĺ��̣���
����
1�����幹��Z-ASCII�ļ�����ѡ����
a�������ĸ�������ʻ���ֱ����ASCII����������Ϣ�����룩���ݵķ�����b�����ö�ʮ�߸��������ʻ��������ASCII���ݵķ�����c�����ʻ���ѡ����Ҫѡ������Ӳ����Ӳ��ϡ�����ľ���ת����ʽ��
2�����幹�ɡ����������֡����������塢������ã���Ϣ����ϵͳ���ļ�����ѡ����
a��GTCM�ġ�0-4�����зֽ�ġ�������Ϣ���Ƿ�Ҫ���ã�������ΪӦ�����ã����ң�GTCM��Z-ASCII���������á�Ȼ��������ͨ�еġ��ִ��������磺����ASCII��GBK��Unicode���ִ�����ʽ���磺FONTS�ֿ⣩��û��Ҳ�����á�b��GTCM�ġ�4-6�����з����ġ��ּ���Ϣ���Ƿ������ȫ���ɡ���ʵ��֤�������ԡ�c�������ϵ���GTCM�ġ�4-6�����ġ�GSCM���ġ�1-m�����ġ���-���顱�Լ����ּ���Ϣ���Ƿ���١���ʵ��֤�����ڡ������ȫ���ɡ��������¡�����١�����������������ɡ���d��GTCM�ġ�5-12�����з����ġ�������Ϣ���Ƿ���١���ʵ��֤������5-8�� ���з����ġ��ʷ��䷨��Ϣ������9-10�����з����ġ��·���Ϣ���롰11-12�����з����ġ������Ŀ��Ϣ���ڡ������ȫ���ɡ��������¡�����١�����������������ɡ���e��GTCM�ġ�0-12�����з����ġ�������Ϣ���Լ���GSCM���ġ�1-m�� ���з����ġ�������Ϣ���Ƿ���١��ɹ�ͨ����ʵ��֤�����ڡ������ȫ���ɡ��������£��������������͡���ע������������Ϣ������ʽ��������١��ɹ�ͨ��������ͨ�е������Ƿ���ġ�������Ϊ����һ��ɢɳ���磺����GBK��Unicode��FONTS�еĺ��ֵġ������̶��ṹ�����롰4-6������Ӧ�ġ����Ӵʵ䡱�Լ����ִ����ע���ʷ����������롰7-8������Ӧ�ġ��䷨���������롰9-10������Ӧ�ġ��·����������롰11-12������Ӧ�ġ������Ŀ��������ʹ�������еġ�����ͼ��ݡ�������Ҳ��Ϊû���漰������������ġ�������ʽ�����Ļ�������������ԡ�����������١���ͨ����
������������֯���͵ġ�������Ϣ��������������Ϣ������ϵͳ���̣���һϵ�о��幤��Ҫ������Ŀǰ����Ҫ��Ӧ�ǡ������ʽ�����롰����ּ�ӵ���ʽ�������ֱ����·��ѡ�����⡣
ע�ͣ�
1������ȫ��ָ�����ں����Ҽ���Ӣ��ġ��й�����Ϣ�����롱��Z-ASCII�����ǡ�Эͬ���ܼ����������ݿ��������ı���������ģ����GTCM������һ���������ġ������ż�����2����������ָ������Z-ASCII�ĺ�������Ϸ��ż������漰��Эͬ���ܼ����������ݿ��������ı���������ģ����GTCM�����ڶ���ʮ���������������У��������߸������������ֱ�λ������ɶ�Ӧ��ת��Ϊ��������������ģ����GSCM������1��m����������3�������ײ�ʽ�����Ժ�����ԣ������飬����GTCM������ʮ����13�������������У��������߸��������ȼ���GSCM��1��m����������4����Ȼ���Դ����ġ���������ģ�͡����Ժ�����ԣ����ǣ�GTCM������ʮ����13����������GSCM��1��m����������5������ġ��ı���������ģ�͡�������GTCM������ʮ����13����������6������ġ�������������ģ�͡�������GSCM��1��m����������7�������������ֵĶ���������黮�����ֻ�������������黯��8������ע��������������Ϣ��ע��ͨ�ó�ʶ��Ϣ��ע��ר��֪ʶ��Ϣ��ע��9����˫����й���������֮�֡�����ġ�˫����磺�ԡ���ĸ��Ϊ����ȫ�ġ�Ӣ����ԡ��ʻ���Ϊ����ȫ�ġ����������ġ�˫����磺�ԡ����֡�Ϊ����ȫ�ġ��������ԡ����ԡ��ַ���Ϊ����ȫ�ġ���Ȼ���ԡ���10����m i����ʾ�����ţ���n j����ʾ����š���ȡ����Ȼ�����ġ�ֵ����11�������㷨���Ǵ���ѧ��������ڡ����㷨���������¡�ָ����ը�����㷨��12������������Ĺ�ϵ�����漰����ʽ�����������棬���У������ǣ����������Ĺ�ϵ��13�������ֹ�ʽ���������С�������ֱ�λ�����ۣ�������Ϊ���֡��ǡ��顱���ֻ������͡�����ѡ��ǡ��롰�顱ͳ��Ϊ����������������ֳ��������̾��ǡ�����Ϊ�֡������У��漰���С��ǡ����֡��顱�������衪���ӡ�����зֳ����ǡ��롰�顱�����ڡ���������Ĺ�ϵ���С����������Ĺ�ϵ���ǻ������ڴ���Ҫ�����������顱���͵ġ��ǡ��롰�顱�ġ����ֹ�ʽ���������С�������������������ġ��֡�����Ϊ�����֡������������֡����Χ�ġ��֡�����Ϊ�����֡�����ô�����ڡ������顱�ġ��������顱��ֻ�С��ʹǡ��롰�Ϳ顱�������͡�
���ֹ�ʽ1.���ʹǡ�=��ʵ�֡�+��ʵ�֡�=�����֡�+�����֡���
���ֹ�ʽ2.���Ϳ顱=�����֡�+��ʵ�֡�=�����֡�+�����֡���
���ֹ�ʽ3.���Ϳ顱=��ʵ�֡�+�����֡�=�����֡�+�����֡���
���ֹ�ʽ4.���Ϳ顱=�����֡�+�����֡�=�����֡�+�����֡���
����1.- 4.�ĸ���ʽ��ʵ�������ֵĹ�ϵ��ǡ��һ�����С��ʼ�ƣ��������С������������顱���������顱�������������顱�ġ����ֹ�ʽ���������С����ɻ��������������顱�Ļ��������ֹ�ʽ���������С���ԭ�����ܳ������ʲ�����������ܡ�
14�����˻�Э���������������������ַֹ�Э����ʽ�������ǡ�ʵʱ����ʱ�������������ǡ���������д���������ֲ����������ɲ��á�
��ǰͨ�е����ֽ�������ϵ���ݿ⡱����ʽ�ԡ����ַ��������֡��ġ�ͬ�岢�С��ġ������֮��ֹ�Э������ʽ�ǡ����Եġ�������ǰ̨���桢��̨�����Լ�ǰ��̨ת���ġ��н����ԡ����䡰�����Ƕ������ģ��磺���֡��������ԡ�������ʽ�ķ���������˴��º�����Ϣ������ר�����ٱ�����Ϥ�����Ӣ��������ԡ���ѧ���ķ���Ķ���֪ʶ���ܣ���ǡ�ơ���ʽ��ȫ�ܲ÷족����ˣ�Ҳ������֯���͵ġ�������Ϣ������ϵͳ���̣�
�������������ֽ�������ϵ���ݿ⡱����ʽ�ԡ����ַ��������֡��롰�����ͣ����֡��ġ�ͬ�岢�С��ġ������֮��ֹ�Э������ʽ�ǡ����Եġ�������ǰ̨���桢��̨�����Լ�ǰ��̨ת���ġ��н����ԡ����䡰������Ψһ�ģ���ˣ����º�����Ϣ������ר��ͨ��ֻ����Ϥ�����֪ʶ���ܵ�һ�����棬��ǡ�ơ���ʽ����ˮ��ҵ����������֯���͵ġ�������Ϣ������ϵͳ���̡�
��ͼ��
ͼ1
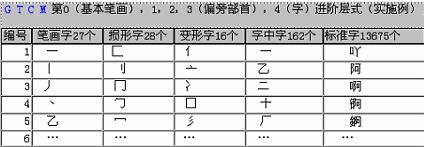
ͼ2
��
��
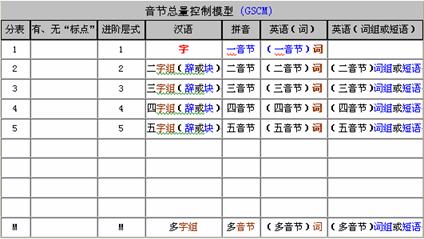
��
ͼ3
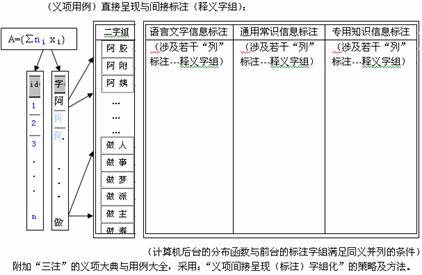
ͼ4
�ο����ף�
��ȫ�ͣ���������[M] 15-120ҳ���Ϻ���ѧ���������磬1978
�й������ѧ��ѧ�����ң����Դ���[M]85-138ҳ��1983
���������ࣺ���������о���չ[C] 1-564ҳ�����ӹ�ҵ�����磬1992
�� ����������������ѧ�о�[M]1-240ҳ����������ѧԺ�����磬1993
���Ƹ���Ӣ���Ա�����ѧ[M] 69-99ҳ��������ҵ��ѧ�����磬1994
��־�������뷽��[M]3-32��225-287��229-304ҳ����������磬1995
ʯ �棺�����о��ں���[M]123-188ҳ����������ѧԺ�����磬1995
�� �d������ʥ����֪����ѧ[M] 344-367ҳ��������ѧ������1996
��־�����������[A]�������ѧ�ۼ�[C]������������磬1996
�����£�����ǿ�ƴ���������ϵ���������[A]����ѧ�ۼ�[C] 1-17ҳ����������ѧԺ�����磬1996
��ͨ�ϣ�������--���������ԵĽṹԭ�����о�����[M] 295-442ҳ������ʦ����ѧ�����磬 1997
½��������������о����ٵ���ս[J���纺���ѧ��1998����4��
ղ����������������ʿ�룺���ڴ��鱾λ�������ģ��[J]�����붫��������Ϣ����ѧ��ѧ��1998��1��
��������HNC�����������磩���ۡ��������������Ȼ���Ե���˼·[M] 1-516ҳ���廪��ѧ�����磬1998
���ӹ⣺�ʻ�����ѧ�ͼ�������ѧ[M60-118��140-376�����ij������꣬1999
��ʿ�롢��ѧ�棺��������ѧ�ļ�[C] 1-254ҳ��������ѧ��������ѧ�о�����2000
ʩ���ֵ��룺���ݿ�����������������ʵ��[M] 170-246��334-489ҳ�����ӹ�ҵ�����磬2001
���������ң�SQL Server 2000 ���ݲֿ���ƺ�ʹ��ָ��[M] 14-69��113-230ҳ���廪��ѧ������2001
��ͨ�ϣ���������ѧ�̳�[M] 19-36ҳ��178-237ҳ��������ѧ�����磬 2001
³ ������������������[M]1-277ҳ������ӡ��ݣ�2001
�����ԣ�һ��֪ʶ��Ϣ���ݴ�����������Ʒ[J]����ר������G06F163֪ʶ��Ȩ�����磬2000����11��
��־ΰ�����Ӻ���ƴ������Ϣʱ��������[A] �����ִ������ļ�[C]41-44ҳ������ӡ���2002
��ʿ�룺���ں�����Ϣ��������ʶ�����о�����[J]��������Ӧ�ã��ܵ�42�ڣ�2002����2��
�������һ��˫�ġ������ۻ��������ٵ�����[A]������ɵȱࣺ�����ִ������ļ�[C] ����ӡ��ݣ�2002
�ƺ������ࣺ���������о���չ[C] 1-282ҳ�����ӹ�ҵ�����磬2002
�����ԣ����Լ�������Ϣ��ͳһ����ϵ[J]DZ��ѧ2002.05
��ѧ�ģ������[M] 44-56ҳ��246-252ҳ���й���ѧ������ѧ�����磬2003
֣��ȫ������ܿ����ͼ[A]����캺��ʻ�����ѧ���ֻ������ļ�[C] 2004
���´����ۺ�������Ԫ���Ե�����[A]����캺��ʻ�����ѧ���ֻ������ļ�[C] 2004
�����ԣ�������������SVDE������������ģ��[A]�����(����)����ʻ�����ѧ���ֻ������ļ�[C] 2004
�����ԣ�Эͬ���ܼ����������ݿ����Ʒ���[J]DZ��ѧ����32�ڣ�2004��7��
�����ԣ��ۺ��������ϸ��[J]DZ��ѧ����32�ڣ�2004��7��
�����ԣ�����ֱ�λ���������ֻ������ģ��ֵ���ʽ������[J]DZ��ѧ����38�ڣ�2004����12��
�����ԣ�����ֱ�λ���������ֻ������ģ����黮�����ֻ�[J]DZ��ѧ����38�ڣ�2004����12��
�����ԣ�����ֱ�λ���������ֻ������ģ���������Ĺ�ϵ[J]DZ��ѧ����39�ڣ�2005����1��
��ѧ�ģ����ַ�����ʽ�������ѧ��[J]��DZ��ѧ����39��2005����1��
�����ԣ�Эͬ���ܼ���֪ʶ���ݿ����Ʒ���[J]DZ��ѧ����39�ڣ�2005��1��
�����ԣ��ع������������ϵ������˼·���·��������ӡ��������ǡ��������ϵ���ٵ����������⡱[A]������(����)����ʻ�����ѧ���ֻ����ļ�[C]
�����ԣ��Ż���������Ϣ���������·�����ʵʩ�������ӡ�һ�ʷ����������������顱�ٵ���һ�־�����[A]������(����)����ʻ�����ѧ���ֻ����ļ�[C]
�����ԣ���������������Ĺ�ϵ��̽����������ʽ������·[J]DZ��ѧ����41�ڣ�2005����3��