The objectivity of the generalized entropy and the generalized mutual information may be examined by a discussion on their coding meanings.
HQ(X)=
-
![]() Q(xi)logQ(xi).
(21)
Q(xi)logQ(xi).
(21)
The coding makes
HQ(X)£ L£ HQ(X) +e
possible, where e is an arbitrarily small positive number (the coding must be possible according to one of Shannon's coding theorems), then this coding for actual source P(X) can make the average code length approach the probability forecasting entropy H(X) (defined by Equation (18)).
Proof Let Li be the code length of xi, then the average code length is
L=
![]() Q(xi)Li.
Q(xi)Li.
Comparing this equation with Shannon's distortionless coding theorem of discrete memoryless source, we have
Li= - logQ(xi)+ei,
![]() Q(xi)ei=e.
Q(xi)ei=e.
![]() P(xi)Li=H(X)+
P(xi)Li=H(X)+
![]() P(xi)ei,
P(xi)ei,
With the inequality logx £ x-1, we can prove that H(X) is greater than or equal to Shannon's entropy of actual source P(X) ( Aczel and Forte 1986). Therefore, the more consistent Q(X) is to P(X), the shorter the average coding length is.
We code X according to Q(X) before receiving the information so that the average code length is close to H(X), and code X according to Q(X|Aj ) for j=1, 2, ..., n after receiving the information so that the average code length is close to H(X|Y). Obviously, the saved average code length is close to the generalized mutual information I(X;Y)=H(X)-H(X|Y). Note that if the forecast always conforms with the fact, then the average code length for the given forecast can infinitely approach Shannon's condition entropy and hence the saved average code length is Shannon's mutual information.
The negative infinite information means that if one codes X according to a wholly false forecast, the increment of average code length will be infinitely long. The coding meaning of the generalized mutual information is further examined in the following sections.
![]() (22)
(22)
![]() , (23)
, (23)
Definition 4.3.1 Let P(Y) be a source and P(X) be a destination (contrarily). Clear sets A1, A2, ..., Am are called the error-limiting sets, if
![]() i=1,
2, ..., m; j=1, 2, ..., n,
(24)
i=1,
2, ..., m; j=1, 2, ..., n,
(24)
![]() is
the complement set of Aj, Q(
is
the complement set of Aj, Q(
![]() |xi) is the feature
function or the membership
|xi) is the feature
function or the membership
grade of xi in
![]() . Let us call
. Let us call
![]() , (25)
, (25)
The function R(AJ) is different from function R(D) since it gives a limit for each yj. For example, in transmitting data 1, 2, ...ÎA, the limit is Aj={i||i-j|1} for j=1, 2, ..., which means that once the deviation is greater than 1, the entire transmission is failing.
Theorem 4.3.2 Let the distortion dij =0 for xiÎAj and dij =¥ for xiÏAj , for each i, j; P(Y) be a source and P(X|Y) be a channel. There is
![]() =H(Y). (26)
=H(Y). (26)
Proof Let us first prove R(AJ)=H(X) with the Lagrangian multiplier method. After analyses we know Shannon’s mutual information IS(X;Y) does have the minimum value. We need to seek the minimum of IS(X;Y) under limiting conditions given by Equation (24) and
![]() P(xi|yj)=1.
(27)
P(xi|yj)=1.
(27)
Let
![]() , (28)
, (28)
![]() , i=1, 2, ..., m;
j=1,
2, ..., n, (29)
, i=1, 2, ..., m;
j=1,
2, ..., n, (29)
where lj
is a normalizing parameter. Since for each xiÎAj
,
![]() ; thus
; thus
![]() , i=1, 2, ..., m;
j=1,
2, ..., n. (30)
, i=1, 2, ..., m;
j=1,
2, ..., n. (30)
From Equations (25), (29), and (30), We can conclude that when
P(xi|yj)=P(xi)Q(Aj|xi)/Q(Aj)=Q(xi|Aj), i=1, 2, ..., m; j=1, 2, ..., n (31)
IS(X;Y) reaches its minimum. From Equation (31) and Shannon's mutual information formula,
we have
![]() . (32)
. (32)
Now let us prove R(D=0)=H(Y). From the classical rate-distortion theory, we know that when
R(D)=sD+
![]() ,
,
![]() , (33)
, (33)
where s is a multiplier less than 0. Since when D=0, dij=0 for xiÎAj and dij= ¥ for xi ÏAj. Thus
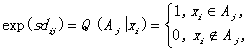 i=1, 2, ..., n;
j=1,2,..., m.
(34)
i=1, 2, ..., n;
j=1,2,..., m.
(34)
and 1/lj=Q(Aj) for each j so that
R(D=0)=
![]() =
=
![]() . Q.E.D.
. Q.E.D.
If some of sets in AJ are fuzzy, i. e. Q(Aj|xi)Î[0,1], and the limiting sets are determined by inequality
![]() , for all P(xi|yj)¹0,
i=1,2,...,n;
j=1,2,...,m.
, for all P(xi|yj)¹0,
i=1,2,...,n;
j=1,2,...,m.
Then we can conclude
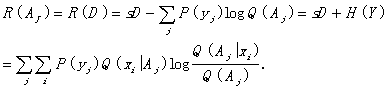 (35)
(35)
This is Shannon’s mutual information as the special case of the generalized mutual information when the prediction is always vaguely true.