��������ģ�ʹ�Hartley��Ϣ��ʽ�Ƶ���������Ϣ��ʽ
³���� (�����о���)
ժҪ��Ϊ�˰Ѿ�����Ϣ���ƹ㵽�ճ���Ϣ����(��������ͨ�źо�ͨ��)������ͨ������ģ�ͣ�ֱ�۵�˵������δӼ�Hartley��Ϣ����ʽ��һ��һ���ƹ㣬�õ�������Ϣ����ʽ����һ������Ϣ��ʽ����������Shannon��Ϣ��Popper֪ʶ�����۵�������
�ؼ�����Hartley��Ϣ�� Shannon��Ϣ��Kullback��ʽ��������Ϣ���о���Ϣ��������Ϣ��Popper����
Deducing General
Information Formula from Hartley��s Information Formula
with the Help of
Fish-covering Model
Lu Chenguang
(independent researcher)
Survival99@hotmail.com
Abstract: To
extend the classical information theory to daily information exchange including
linguistic communication and sensory communication, this paper intuitively
explains, with the fish-covering model, how to extend simple Hartley��s formula
of information amount to the formula of general information amount step by
step. The later formula happens to be a bridge between
Keywords: Hartley
information, Shannon information��Kullback
formula, measuring information,
sensory information, semantic
information, Popper��s theory.
1��
����
�����ڡ�������Ϣ�ۡ���1��������Ĺ�����Ϣ��������ʽ��Hartley��Shannon�ľ�����Ϣ��������ʽ����Ȼ�ƹ㡣Ϊ��ʹ��Ҹ��õ����������Ϣ��ʽ�ĺ����ԣ����Ľ�������ģ�ͣ���Hartley��Ϣ��ʽ���Ƶ���������Ϣ��ʽ��
2 Hartley��Ϣ��ʽ��ͼ��ͨ�ŵ�����ģ��
Hartley��Ϣ��ʽ��2����
I=logN
(1)
����I��ʾȷ��N���ȸ����¼��е�һ������ʱ�ṩ����Ϣ������¼�y�Ѳ�ȷ����Χ��N1����СΪN2������ô��Ϣ�͵���
Ir=I1-I2=logN1-logN2=log(N1/N2)
(2)
�����ҳ������ʽ��Hartely�����Ϣ��ʽ����˵�������ʽ����֮ǰ���ҽ�һ���������Ӳ���Ĺ��¡�
���������������ģ����ȥ�Ҽһ����õĿ����֣��������ǣ������и�Բ�ڣ�����ץ�㡣���ʺ�dzˮ���㡣��Сʱ���˼��������Ӳ��㣬��Ҳ�ø�ͨ�˵�����ѧ�Ų���Ҳ�沶���ˡ��������ܽᾭ�飺�����Ӵ�������ס�㣬������ס�Ժ�ץ������Щ����������Ӻͳ���һ�����ǾͰٷ����У�����û�����壬��ΪҪץ���㣬����һ�����ѡ��������ӻ�С���������㣬��Ȼ�������ѣ������ֵ��ˣ�ץ�ͺ����ס�
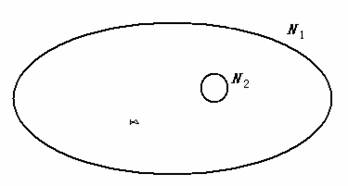
ͼ1 ������Ϣ������ģ��
һ����ȷ���¼������dz�����������ֵ�һ���㡣�����y=����ס���ˡ���y���ṩ�������λ����Ϣ����N1�dz����������N2�������ӵ������ ��ô��Ϣ����I=log( N1/ N2)��N2���N1ԽС����Ϣ��Խ��������ӳ�����ӵ��ŵ㡣��N2= N1ʱ����Ϣ��0�� ������ӳ�������Ӻͳ���һ��������Ҳû�����塣���������Ӻ�������ȵ��ŵ�(�����׳���)�����湫ʽ���ܷ�ӳ����Ϊʹ��Hartley��ʽ��������ǰ����¼���Ȼ��N2���¼��е�һ�����൱�ڼ��裺�����ӻ����Ӳ����ֲ����㡣�����Ƶ����Ĺ�����Ϣ��ʽ�����ݡ��ֲ��С������
3 ģ�Ľ��D�D�¼��ռ��Ϊ�����Կռ�
��Hartley��ʽ������Ϣ��Ҫ��N���¼��ǵȸ��ʵ�, ��P=1/N������ͨ�������������ˡ� ���磬����ˮ��ĵط������Դ�Щ����ˮdz�ĵط�������СЩ����ʱ����δ����� ��ʱ��������ʵ�ʵĸ��ʴ���������ȵĸ��ʣ�����P1����1/ N1, ��P2����1/ N2�����ǣ�Hartley��Ϣ��ʽ�ͱ�Ϊ
I=log(1/P)
(3)
����������Ϣ��ʽ�ͱ�Ϊ��
Ir =log(P2/
P1)
(4)
4���Լ���Ϊ�����������Ϣ��ʽ
������������λ��Ϊ�������X, ��ȡֵ�ڼ���A��Ԫ�أ�
A={x1, x2,
��}; ����¼�Y�ǹ���X��������(�������Ӹ�������)�ı��棬Yȡֵ��B��Ԫ�أ�B={y1, y2,��}��
yj=��xi ��Aj��(��xi�ڼ���Aj�С�)����ʱ�� P1��д��P(xi), P2��д��P(xi|xi ��Aj)�� ���Ǽ��P(xi|Aj)= P(xi|xi ��Aj)��P(xi|Aj)���Լ���Ϊ�������������ʡ��������������Ϣ��ʽ��Ϊ
![]()
(5)
�����ʽΪ���Լ���Ϊ�����������Ϣ��ʽ����Ϊ����������ģ�ͣ����dz�֮Ϊ��������Ϣ��ʽ����ֵ��ע����ǣ�һ������£��Լ���Ϊ��������������P(xi|Aj)�������yjΪ��������������P(xi |yj)�Dz��ȵġ�
P(xi|yj)= P(xi|��xi ��Aj��)=P(xi |��xi ��Aj�� ������)
(6)
����yj���ܲ���Ҳ�����ǻ��ԣ�Ȼ��xi ��Aj��ʾyjΪ�档��
P(xi|Aj)= P(xi|xi ��Aj)=P(xi |��xi ��Aj�� ��)
(7)
���������ȣ������棨Ԥ�Ի����⣩������ģ������Ǻ���ʵһ�£���ô���湫ʽ�ͱ�Ϊ������Ϣ����ʽ��2����
![]()
(8)
������ƽ���͵õ�Shannon����Ϣ��ʽ��
5��������Ϣ��ʽ�����ʼ������ڲ�����Ϣ�Ķ���
�����������¶Ȳ���Ϊ����˵�������������Ϣ��ʽ����������Ϣ��
һ���¶ȶ����ɿ�����һ�����������Ӹ�������ı��棬ʵ���¶ȿɿ������λ�á���������ģ�Ϳ��������¶Ȳ����������¶ȼ���A={x1,
x2, ��}���¶ȶ�������B={y1,
y2,��}, X��Y�DZ�ʾ�¶Ⱥ��¶ȶ�����������������Ҷ�����Y= yj
ʱ�������ܵ��¶���xj �����衰�����ӡ�����������������yj ʱ�� ʵ�ʵ��¶�Ӧ��ij��ȷ����ΧAj�ڣ�
����Aj =[xj-0.2,
xj+0.2]�����ǣ�ʵ��xi����ʱ��yj�ṩ����Ϣ�������������Ϣ��ʽ��5����ʾ��
�������Dz�����֤����yjһ����ȷ��������������������������������Ϣ���Ǹ���(��������ʱ��Ϣ�Ǹ������)��
�輯��Aj������������Q(Aj|xi)(ȡֵ0��1���ʾ���)��
����Bayes��ʽ�� ��
P(xi
|Aj)=Q(Aj | xi )P(xi )/Q(Aj
)
(9)
����Q(Aj)��Q(Aj
| xi )��ƽ��ֵ����
![]()
(10)
��(9)��(10)�����ǵõ�������Ϣ��ʽ����һ����ʽ��
![]()
(11)
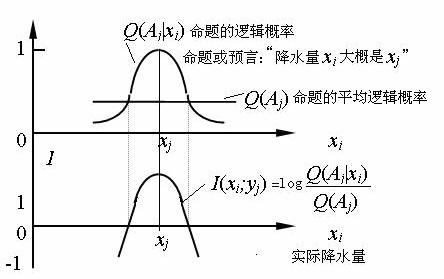
���Ǿ�����Ϣ��ʽ������Ϣ��ʽ֮��Ĺ��ɡ��������������Ϣ����xi�ı仯��ͼ2��ʾ��
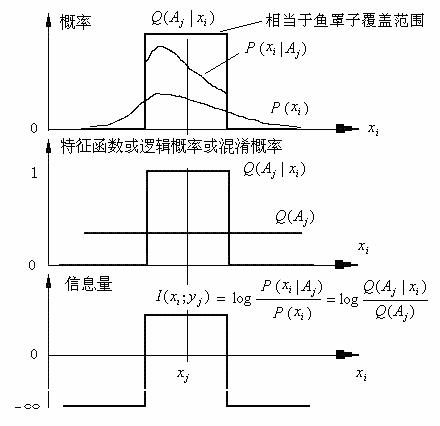
ͼ2 ������Ϣ��ʽͼ��
6��������Χģ��ʱ�IJ�����Ϣ�ͽ�ˮ��Ԥ����Ϣ�D�D������Ϣ
�¶Ȳ��������ṩ����Ϣ�ͽ�ˮ����ֵԤ��(���磺����ˮ����Լ��
I=m-k|xi-10|
(12)
�ͱȽϷ��ϳ�ʶ(�ο�ͼ3)��
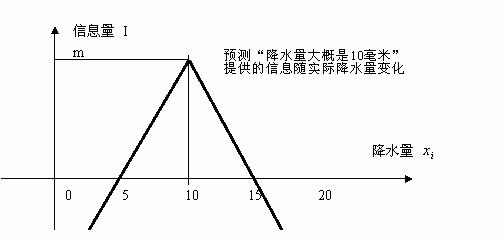
ͼ3 һ������Ľ�Ϊ���ϳ�ʶ����Ϣ����ʽͼ��
���ǹ�ʽ(12)���ܼ���������Ԥ��D�D����ˮ����С��
���������Ƶ���һ����������ʽ(12)�ŵ㣬Ҳ���ֲ���ȱ�����Ϣ��ʽ��
�������Ǽٶ���Aj���������ϡ���������Q(Aj|xi)������Ϊxi��xj������ĸ��ʡ�������������Aj�����xi��Aj�У�����������1�� ������0����ʵ������ǣ�Aj������ģ���ģ��������ʿ�����0��1֮��仯��
��������ʵ������ģ�������������Լ����������ʵIJ�ͬ˵������������Q(Aj|xi)����������������ͳ�ơ�4��(�ο�ͼ4)��
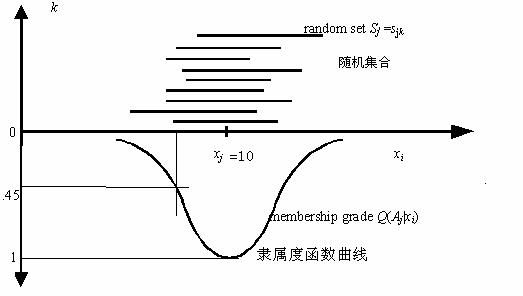
ͼ4 ��������(�������Ȼ�������)������������������������������ͳ��
���������ǣ�������������������飺������Y= yjʱ���ı�xi, ֻ�е�xi��xj�����һ���̶ȣ�����yj�Ż�仯�� ����������仯������xi���ɵļ�����һ���������ϣ������(��Ϊn->�����)����õ����������ļ���sj1, sj2,��sjn��Ȼ�����Ƕ���
![]()
(13)
��xi��xj ������Ļ������ʣ� ��Ҳ����xi��ģ������Aj �ϵ������ȣ�������yj=�� xi��ģ������Aj�С��������ʡ�����Q(sjk|xi)�Ǽ���sjk���������� (����0��1)��
Ҫ���������Χģ��ʱ���¶Ȳ�����Ϣ�� ����ֻ��Ҫ�û������ʺ���ȡ��ǰ��ļ���������������ʽ��ʽ��ͬ(11)���ǣ�
![]()
(14)
����ǹ�����Ϣ(��)��ʽ����ͬ���ǣ�����Q(Aj|xi)��ɽ�κ��������Ǿ��κ�����������Ϣ��ʽ��������Ϊ�����ӱ߽�ģ��ʱ��������Ϣ��ʽ��
��ʽ(14)�ļ���������ͼ5��ʾ������������������yjʱ��
ʵ�ʷ�����xi ��xj���Խ����Ϣ��ԽС������һ���̶ȣ���Ϣ�����Ǹ��ģ�Q(Aj)ԽС����Ϣ�ľ���ֵԽ��
�������ʽ��������ͼ����Ϣ�� ��ХԤ����Ϣ�����ͼֽ��Ϣ��Ҳ�ǿ��е�[1]��
7���о���Ϣ����
�����ҿ���������Ӧ��ͬ�Ҷȵȼ������ص��Ӿ���Ϣ������Ҷ���X��xi, ��Ӧ�ĸо���Y=yj ,
���к�xj�������xi����ģ������Aj, Q(Aj|xi)�����۰�xi��xj������ĸ��ʡ� ���ǣ��Ӿ���Ϣ���¶Ȳ�����Ϣ�ڱ�������ȫ��ͬ���ù�ʽ(14)�Ϳ��Զ���һ�ֻҶ��Ӿ�yj�ṩ�Ĺ���xi��Ϣ���ݴˣ����߸��ݸйٷֱ����Ż�ͼ��ͨ�ŵõ�������������ۣ��ο����ס�5����
8��������Ϣ����
�ڱ��߿�����Ԥ����Ϣ�DZ���ʵ������Ϣ������һ���Ե�������Ϣ����Ԥ�����ʵһ��ʱ�� Ԥ����Ϣ�ͱ�Ϊ��ʵ������Ϣ�����ԣ�����һ��������Ϣ���뿼��Ԥ�����ʵ�Ƿ�һ�¡�
�����Q(Aj|xi)(��0��1֮��仯)����Ϊ����yj�Ŀ��ŶȻ������ʣ���ʽ(14)�Ϳ������ڶ���������Ϣ��Ԥ����Ϣ(�ο�ͼ5)����ʱ�����ǿ��Լ�����Ӧÿ������yj����һ������ͼʽ������xj(���ܲ���Aj��)�� ����yj(xj)�Ŀ��Ŷ���1�����������ǾͿ���Q(Aj|xi)����Ϊxi������xj������Ļ������ʡ�����������Ϣ�Ͳ�����Ϣ�ڱ�������ͬ��
ͼ5
������Ϣ(������Ϣ���о���Ϣ��Ԥ����Ϣ)��ʽͼ��
����֤�����ù�ʽ���ڡ�������С�����ꡱ�����ķ���ֵԤ�����Ϣ����Ҳ�Ǻ����ģ���Ԥ�ⲻʱ�������Ϣ��(�����Ǹ���)Ҳ�Ǻ����ġ�1��������Ϣ��ʾ�����Ԥ�����Ի�����������е���Ϣ��
�����Q(Aj)Ҳ����˵��ν��yj(X)��������, ������yj�����������ʻ�ƽ�������ʡ����ǣ�������Ϣ����ʽ����д�����������������ʽ

(15)
9������Kullback��ʽ�����廥��Ϣ��ʽ������ͨ���Ż�
���ǶԹ�����ϢI(xi; yj)��ƽ���� �͵õ�����Kullback��ʽ
![]()
(16)
���ж��������P(xi)Ҳ���Բ�������ͳ�ƣ������������۹��ƣ���ʱ�����Ǽ���ΪQ(xi)����ʱP(X|Aj)��ΪQ(X|Aj)������Kullback��Ϣ��ʽ�����ʿ���ͨ��ͼ6˵����

ͼ6 ����Kullback��ʽ����ͼ��
����֤����Ԥ��Q(X|Aj)����ʵP(X|yj)Խ���غϣ���Ϣ��Խ�� ��ԴP(X)���������Q(X)Խ������ʵP(X|yj)��ͬ(��ʾԤ�������Խ�dz�������)����Ϣ��Խ�����Popper�Ŀ�ѧ������������һ�µ�(���潲��)����Q(X|Aj)��P(X|yj)ʱ�����湫ʽ�ͱ�ΪKullback��ʽ���ٶ�I(X; yj)��ƽ�������ǵõ����廥��Ϣ��ʽ
I(X;Y)=H(X)-H( X|Y)=H( Y)-H( Y|X)
(17)
����
![]()
(18)
![]()
(19)
![]()
(20)
![]()
(21)
���У�H(X)����֮ΪԤ���أ�����ӳ����Ԥ�����Դ��ʵ����Դ��һ��ʱ�������ŷ�ʽ�����ƽ���볤���ޡ�H(X|Y)����һ�鼯��Aj, j=1,2,�� Ϊ�����ĵ������ء�H(Y)�ǹ����أ�����������ʱ������ӳ����������Ƽ���ʱ�����ƽ���볤��1���� ���ɾ��Ǹ����������еĸ�����ʧ����(rate -complexity-distortion)��6����H(Y|X)�ǹ��������ػ�ģ���ء�����֤��Deluca-Terminiģ���ء�7��������ģ���ص�����������֤����ģ���Ի������Ϣ�ľ���ֵ��������Ԥ�ⲻ������£�ģ���Կ��Լ�С����Ϣ����������Ӵ�����������ͬ������Ҳ����ΪʲôԤ�ԼҴ��ϲ��ʹ��ģ�����ԣ�Ϊʲô���ڿ��ܲ�ȷ��Ԥ�⣬����������ģ�����⡣���ڸо���Ϣ���йٷֱ��ʵ���ģ���ش���Ϣ��С����һ���棬���й۷ֱ��ʻ��С������������Ϣ��ʧ�������Ϊʲô����ͼ��ѩ�������ʱ�����ԶЩ���Ӿ�Ч��������Щ��
���廥��Ϣ��ʽ���Ż�����ͨ��������Ҫ���塣������Ϣ��ʧ�������о�����ͨ���Ż����⣺����ʧ�����ƣ�Shannon��Ϣ������ı��أ�������Ҫ���٣������ǣ��ڸ���Shannon��Ϣʱ��ʧ�淶Χ��С�ɴ���١���ϧ����ʧ������Ϊ����ģ�û�п۱����������˹�����Ϣ��ʽ�����ǾͿ����ù�����Ϣ�����ʧ������Ϊ����ͨ������������Ϣ��ʧ���۸Ľ�Ϊ��������Ϣ���ۣ��ɴ˿��Եõ�������Ҫ���ۡ�1�������磺�������������ſڿ�������������е���Ϣ��Ҫ�û����Ի���ˣ�Ҳ��Ҫһ���Ŀ���Ϣ�����۸йٷֱ��ʺ�ͼ��֮���������ƥ�䣬�Ӿ��ֱ������ޣ�ͼ��̫�߷������á�
����������Q(X)������ԭP(X), Ԥ����H(X)�ͱ�ΪShannon�ء���һ���������ʵP(X|yj)����Ԥ��Q(X|Aj)����ô����P(yj)��Q(Aj)(��������j), ������H(Y)Ҳ��ΪShannon�أ����廥��Ϣ�ͱ�ΪShannon����Ϣ���ɼ���Shannon����Ϣ�ǹ��廥��Ϣ��Ԥ�����ʵ����һ��ʱ��������
10�� ������Ϣ��ʽ��Popper��ѧ�����۵�һ����
������Ϣ��ʽ(14)��������ͼ7��ʾ��Ϊ�˱������⣬���Dz�����ͼ��Ԥ������Ϊ�Թ���ָ������ˮ�����¶������������Ԥ�⡣����ɽ�����߱�ʾ������ͬԤ��D�D���ԱȽϾ�ȷԤ���ģ��Ԥ�⣬ �Ը�żȻ�¼���Ԥ��ͶԲ���żȻ�¼���Ԥ�⡣ͼ�н��ۣ���ȷԤ����Ϣ�ľ���ֵ���������׳������������¸���Ϣ���Ѹ�żȻ�¼�Ԥ������Ϣ������
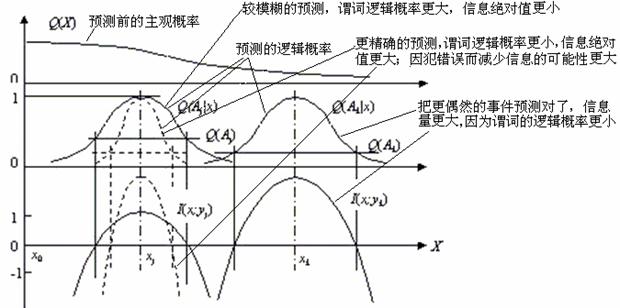
ͼ7 ������Ϣ��ʽ������
���ڿ�ѧ���۵Ľ�������Popperд����
�����ǰ����������ľ�����Ϣ�����ݵ����ۣ�Ҳ�������ϸ����������ۣ����Ǿ��и���Ľ�������Ԥ���������ۣ��Ӷ�����ͨ������Ԥ�����ʵͬ�۲���ԱȽ϶���������ϸ��������ۣ���Ϊ��ȡ����֮��������ȡһ����Ȥ������Ϣ�ḻ�����ۣ�����ȡһ��ƽӹ�����ۡ�����8����
����Popper��֤α���ۣ�����������Խ���ױ�֤α(Ҳ����˵������Q(Aj)ԽС)������ʵ�Ͼ��������(Ҳ����˵Q(Aj|xi)Խ��)�������ṩ����Ϣ��Խ�࣬��Խ�����塣��֮�������ϲ��ܱ�֤α����������(Ҳ����˵Q(Aj|xi)��Q(Aj)��1)��������Ϣ��û�п�ѧ���塣
�ɼ�����Ȼ������Ϣ��ʽ�Ǿ�����Ϣ��ʽ����Ȼ�ƹ㣬��������Popper�Ŀ�ѧ�������о��˵�һ���ԡ�
�����
[1]³���⣬������Ϣ�ۣ��й���ѧ������ѧ�����磬1993
[2]
Hartley, R. V. L. Transmission of information,
[3]Shannon,
C. E. A mathematical theory of communication��Bell System Technical Journal,27 (1948)��379��429��623��656
[4]����ׯ�� ģ�������������Ӱ������ʦ����ѧ�����磬1984.
[5] Lu,
Chenguang (³����) ��A generalization of Shannon's
information theory" , Int. J. of General Systems, 28: (6) 1999��453-490
[6]Li, Ming and Vitanyi, Paul, An Introduction
to Kolmogorov Complexity and Its Applications,
[7] De Luca A. and Termini��S.: A definition of nonprobabilistic entropy in the
setting of fuzzy sets��Infor. Contr. 20(1972)��201��312
[8]��Ӣ�����ն��������ص���, ����ͷ���������ѧ֪ʶ���������Ϻ����ij����磬1986