The Comparison of My
Information Formula and Floridi��s Information Formula
Abstract: Floridi considered the matters of truth-False and
always-true-propositions in setting up his semantic information formula, but
the matter how the size of logical probability of a proposition affects
information amount as Popper pointed out. Floridi��s information formula is also
not compatible with
Key word: semantic information, formula, Popper, Shannon
�ҵ�������Ϣ��ʽ��Floridi��������Ϣ��ʽ�Ƚ�
³����
ժҪ��Floridi�Ľ���������Ϣ��ʽʱ�����˶Դ�����������������⣬ ����û�п���Popperָ�������������ʴ�С����Ϣ���Ĺ��ף� Ҳ����Shannon��Ϣ��ʽ���ݡ� ���Ľ��ҵ���Ϣ��ʽ��Floridi����Ϣ��ʽ���˱Ƚϣ� ��ͼ˵���ҵ���Ϣ��ʽ���Ӻ�����
�ؼ��ʣ�������Ϣ����ʽ��Popper, Shannon
1. ����
����������Ϣ���뿼����ʵ���顣 �ͼ�����˵�� Floridi��˼·���ο���¼�� ժ��[1]�����ҵ�˼·��һ���ġ�����Ϊ�� ������Ϣ����ʽҪ�ܱ�֤��
1)�Դ����⣻˵������Ϣ�Ͷ࣬
˵������Ϣ���١�������˵���������ꡰ�� ʵ���ϵڶ���û���꣬ ��Ϣ���٣���˵�Ǹ��ģ�������ڶ������꣬ ��Ϣ�������ģ�
2)�������ⲻ������Ϣ�� ����������磺����������Ҳ�������ꡱ����һ��һ���ڶ�����
3)��żȻ�¼��������¼�Ԥ���ˣ���Ϣ����������˵���������ش��ꡱ��żȻ�¼������������������1.9%, ������0.1%��(�����¼�)�����˵���ˣ���Ϣ��������Popper�Ļ���˵���ǣ�Ԥ�⾭������Ͼ��ļ���[2]�� ����Ϣ���ݸ��ḻ��
4)��Shannon��Ϣ��ʽ[3]���ݡ�
Floridi ������Ϣ��ʽ��ʱ��ݿ�����ǰ�������⡣û�п��Ǻ��������⡣
��������ͨ�������Ƚϣ���Floridi����Ϣ��ʽ���ڵ����⡣
2.
Floridi��������Ϣ����ʽ
������˵����ʵ=���������������������ͣ�����Ԥ�⣺
(T)���������У� Ҳ����û�п����������ͣ�
(V������һЩ���������ͣ�
(P�������������������͡�
���У� ��һ����T�����������⣬ ��������Ϣ�� �ڶ�����V����Щ��Ϣ�� ��������P����Ϣ�����
Floridi��w��ʾ��ʵ,
�ұ�ʾԤ��ֵ���ȱ�ʾ��ʵw���ҵ�֧�ֶȡ���
��(��) = 1 − ��(��)2
��1��
��ʾ��Ϣ�ȣ�degree of informativeness���ο���¼Figure 5)��
��Ϣ�Ȼ�������Ϣ��������֧�ֶ��Ȼ��ֲ�����Ϣ����Ԥ����ṩ����Ϣ�Ƕ����أ�Floridi˵������
��(��) = log(�� − ��)
(2)
����������������Ϣ������2/3�� ���������ұ߲��֣�Figure 6����Ӱ���֣���������Ц���V�ṩ����Ϣ������0.24479�������Һ���˵�����������ʣ�
������Ϣ����ʽ��2����ʲô�����أ�
1)���ܱ�֤������˵��1)��2)�� ���Dz��ܷ�ӳPopper���������飬
�Ǿ��Ǹ����żȻ�� ������������Ը��ߵ����ۡ� ���磬����Ԥ�⣺P1���������п��˨D�D����ͷ��һŮ���D�D�������͡���
���˵���ˣ���Ϣ��Ӧ�ø���Floridi�Ĺ�ʽ���ܵõ�������ۣ���Ϊ��(��)�������ޣ� ����1.
2)Ϊʲô��ʵw��P��֧�ֶ�����0? Ϊʲô����1? ��Ȼ�����w��P��֧�ֶ��ȣ�1, �͵ò������ۨD�DP����Ϣ����� Floridi������˵��P��������������0���С���������Ĺ�ʽ���ܷ�ӳ����ͺ������⡣
3)������ʵ��10�����ˣ�P��˵��3�����ˣ�
˵���ˣ�����Ϣ���Ƕ��٣���ʱ��ʽ��δ������˷ѽ⡣
4)��Shannon��Ϣ����ʽ���̫Զ���������⡣
����Ϊ����ĸ�Դ��Floridiû�п��������������ٺͺ������ٵ���������T֮���Բ��ṩ��Ϣ�� ����Ϊ���������黹�Ǻ��飬��������ģ� ��Pֻ�к�������ģ� ����Ϊ��Ŀ����Ժ�С��
3. �ҵ�������Ϣ����ʽ
���ù���ָ��Ԥ����˵���ҵ���Ϣ����ʽ�� ��Ϊָ��Ԥ��ȿ�������Ԥ�������һ���ԡ�
������Ϣ���õ��ĸ��ʿ�νͳ�Ƹ��ʣ�����ӳ������ٵĸ����������ʡ���������ο�ͼ1��

ͼ1 ͳ�Ƹ��ʺ������ʱȽ�
���ǿ���ͳ��ij�����ж���������������Ƶ�ʣ� ��������һ���̶Ⱥ����Ƶ�ʣ���0��1֮�䣩������ij��ȷ��ֵ�����ֵ���Ǹ��ʻ�ͳ�Ƹ��ʡ����������������ʵxiһ��ʱ������yj��yj(xi)����ͬ�����ж�Ϊ��ĸ��ʡ���������yj=��ָ�������ӽ�10������ָ��ʵ������X=10%ʱ���ж�Ϊ�����������1������������������ʽ�����С������5%ʱ�����ʽӽ�0��
����ѧ�ĽǶȿ������ָ��ʵ������ǣ�����P(xi)�� һ���и���֮�͵���1, ��
![]()
��3��
��������Q(yjΪ��|xi)�����ֵ��1�����֮��һ�����1��
����ʹyjΪ�������X����ģ������Aj��������Q(yjΪ��|xi)����xi��Aj�ϵ������ȣ���ô����Ҳ������Q(Aj|xi)��ʾxi��Aj�ϵ������Ⱥ�����yj(xi)�������ʡ�
����yj���ڲ�ͬX��ƽ�������ʣ�Ҳ����ν��yj(X)�������ʣ��ǣ�
![]()
��4��
���Ƕ���������Ϣ��ʽ
![]()
��5��
�京���ǣ�

��6��
��ͼ2�ɼ�����ʵ��Ԥ����ȫһ��ʱ����xi=xj,����Ϣ������������������ ��Ϣ��������С�� ����һ���̶���Ϣ���Ǹ��ġ����Ƿ��ϳ����ġ�
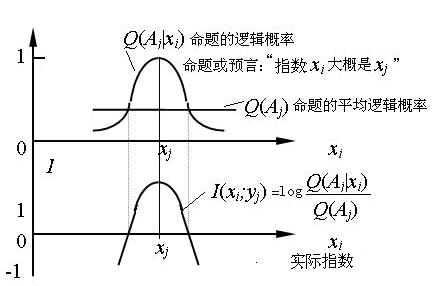
ͼ2 ������Ϣ��ʽͼ��
�������ʽ���Ա�֤��
1)�������⣨���硰����ÿ�������Ҳ���ܲ��ǡ�����Ϣ����0, ��Ϊ����ͺ��������ʶ���1.
2)����������Ϣ���Ǹ��ģ�
3)Խ���ܰ�żȻ���Ƿ��������Ƿ�10%���Ƿ�1%��żȻ��Ԥ���ˣ� ����Խ��Ԥ��þ�ȷ������Ԥ�⡰���������Ƿ���Լ��5%���ȡ�����������ǡ���������ȷ����Ϣ��Խ��
��Ϊ��żȻ�¼���Ԥ�����ȷ��Ԥ�⣬�����ʸ�С����ͼ1 ��ʽ4�ɼ�����
��һ��ʽͬ�����Զ���������Ϣ�������¶ȱ���Ϣ����һ��Ԥ����Ϣ�� �о���Ϣ[3]��
��ȻҲ���Զ�����������Ԥ����Ϣ��
4. ���ҵ���Ϣ��ʽ������������Ԥ����Ϣ
�����������ʽ������Floridi������T�� V, P����Ԥ�����Ϣ��������ʱ��xi����w, ����Ԥ��ĺ��������ʶ���1, �������������ʲ�ͬ��
���ȿ�T�� ��Ϊ���������Ҳ��1,
������Ϣ����������0.
�ٿ�V������������С�㣬������1/4(��3/4�������û�п�����), ����Ϣ����log(1/4)=2���ء�
�ٿ�P�����������ʸ�С��������1/16,
����Ϣ����log(1/16)=4���ء�
����P���P1�����������������˨D�D������ͷ��һ��Ů���D�D�������͡��������������ʸ�С����Ϣ������
��������þ�ȷ�ķ�ʽ��������P�� ���������������������Ϣ���Ǹ���������ճ������У�����������ģ���ķ�ʽ�������ԣ�2����4������Ҳ�������ȷ�� ����P�������ʺ���Ӧ�ô������£�
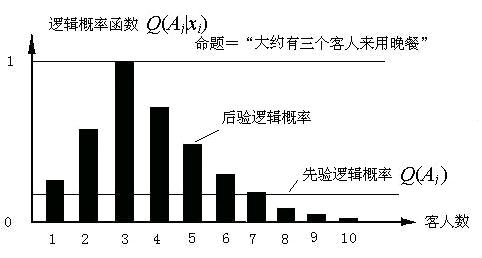
ͼ3 ģ�����⣨����������ģ������ʱ���������ʺ���
��ʱ��Ԥ�ⲻͬ��������ṩ����Ϣ�������Ǹ��� ȡ���ں����������Ƿ�������������ʡ���������Ϣ�����ģ� ������Ϣ��0, С����Ϣ�Ǹ��ġ�����ϳ�����
ģ��������Ҳ��������ͳ�ƣ� �ο��ҵ��������¡���������ģ�ʹ�Hartley��Ϣ��ʽ�Ƶ���������Ϣ��ʽ��[1]������ƪ����Ҳ���Կ������ҵ�����������Ϣ��ʽҲ����ͨ��������Ϣ����ʽI=log[P(xi|yj)/P(xi)]�Ƶ�������
�����ҵ�������Ϣ�о����������ۼ�����[4.5,6]��
�����
[1] Floridi, L., Semantic Conceptions of Information, in Stanford Encyclopedia of Philosophy, see http://plato.stanford.edu/entries/information-semantic/
[2] ���ն�������ͷ���������ѧ֪ʶ������[M]���Ϻ����Ϻ����ij����磬1986.
[3] Shannon, C. E. A mathematical theory of communication[J]��Bell System Technical
Journal, 1948, (27)��379-429��623-656
[4] ³���⣬������Ϣ��[M]���й���ѧ������ѧ�����磬1993.
[5]Chenguang, Lu (³����), A generalization of Shannon's information theory[J]
, Int. J. of General Systems, 1999, 28(6)��453-490
[6] ³����, �����غ��廥��Ϣ�ı�������[J],
ͨ��ѧ��,
1994, 5(6), 37-44.
��¼��Floridi��Ϣ��ʽ˵��
���ο���ҳ��http://plato.stanford.edu/entries/information-semantic/ ��
Suppose there will be exactly three guests for dinner
tonight. This is our situation w. Imagine we are told that
|
(T) |
there may or may not be some guests for dinner tonight;
or |
|
(V) |
there will be some guests tonight; or |
|
(P) |
there will be three guests tonight. |
The degree of informativeness of (T) is zero
because, as a tautology, (T) applies both to w and to ¬w. (V)
performs better, and (P) has the maximum degree of informativeness because, as a
fully accurate, precise and contingent truth, it ��zeros in�� on its target w.
Generalising, the more distant some semantic-factual information �� is from its target w, the larger is the number of situations to
which it applies, the lower its degree of informativeness becomes. A tautology
is a true �� that is most ��distant�� from the world.
Let us now use ���ȡ� to refer to the distance between a true �� and w. Using the more precise vocabulary of situation logic, �� indicates the degree of support offered by w to ��. We can now map on the x-axis of a Cartesian diagram the values
of �� given a specific �� and a
corresponding target w. In our example, we know that ��(T) = 1 and ��(P) = 0. For the sake of simplicity, let us
assume that ��(V) = 0.25 (see Floridi [2004b] on how to
calculates �� values). We now need a formula to calculate
the degree of informativeness �� of �� in relation to ��(s). It can be shown that
the most elegant solution is provided by the complement of the square value of ��(��), that is y = 1 − x2. Using the
symbols just introduced, we have:
[13] ��(��) = 1 − ��(��)2
Figure 5 shows the graph generated by equation [13]
when we include also negative values of distance for false ��; �� ranges from −1 (= contradiction) to 1 (=
tautology):
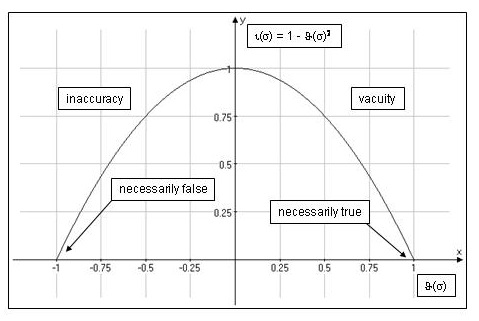
Figure 5: Degree of informativeness
If �� has a very high degree of informativeness �� (very
low ��) we want to be able to say that it contains a large
quantity of semantic information and, vice versa, the lower the degree of
informativeness of �� is, the smaller the quantity of
semantic information conveyed by �� should be. To calculate
the quantity of semantic information contained in ��
relative to ��(��) we need to calculate
the area delimited by equation [13], that is, the definite integral of the
function ��(��) on the interval [0, 1].
As we know, the maximum quantity of semantic information (call it ��) is carried by (P), whose �� = 0. This is
equivalent to the whole area delimited by the curve. Generalising to �� we have:
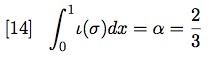
Figure 6 shows the graph generated by equation [14].
The shaded area is the maximum amount of semantic information �� carried by ��:
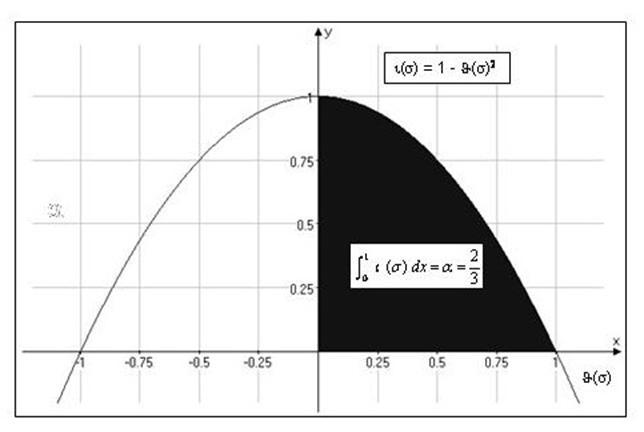
Figure 6: Maximum amount of semantic information �� carried by ��
Consider now (V), ��there will be some guests tonight��. (V)
can be analysed as a (reasonably finite) string of disjunctions, that is (V) =
[��there will be one guest tonight�� or
��there will be two guests tonight�� or
�� ��there will be n guests tonight��], where n is the reasonable limit we wish to consider (things
are more complex than this, but here we only need to grasp the general
principle). Only one of the descriptions in (V) will be fully accurate. This
means that (V) also contains some (perhaps much) information that is simply
irrelevant or redundant. We shall refer to this ��informational
waste�� in (V) as vacuous information in (V). The amount of
vacuous information (call it ��) in (V) is also a function
of the distance �� of (V) from w, or more generally:
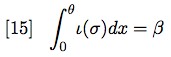
Since ��(V) = 0.25, we have
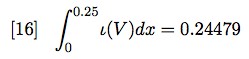
Figure 7 shows the graph generated by equation [16]:
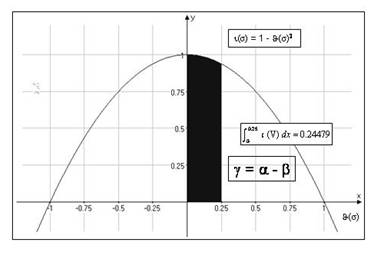
Figure 7: Amount of semantic information �� carried by ��
The shaded area is the amount of vacuous information �� in (V). Clearly, the amount of
semantic information in (V) is simply the difference between �� (the maximum amount of information that can be carried in principle by
��) and �� (the amount of vacuous
information actually carried by ��), that is, the clear area
in the graph of Figure 7. More generally, and expressed in bits, the amount of
semantic information �� in �� is:
[17] ��(��) = log(��
− ��)
Note the similarity between [14] and [15]. When ��(��) = 1, that is,
when the distance between �� and w is maximum, then �� = �� and ��(��) = 0. This is what happens when we consider (T). (T) is so distant
from w as to contain only vacuous information. In other words, (T)
contains as much vacuous information as (P) contains relevant information.