中国古代关于指数爆炸的思考见于“歧路亡羊”的故事:某人的羊丢了,他请村里的人一起去找,不久他愁眉苦脸地回来了,别人问他:“不就是一只羊么,何必如此沮丧。”他说:“不是羊的问题,我想的是,路上有岔路,岔路前头还有岔路,这样算起来村里有多少人也是不会够的。”当然在日常生活中羊是可能找到的,这是一个思考实验,显示了指数爆炸的困难。
外国也有这样的故事。一个国王非常喜欢国际象棋,就召见发明国际象棋的人问他想要什么奖赏,他在棋盘的第一个格里放了1颗麦粒,在第二个格里放2颗,第三个格放4颗,说道:按这样放下去,直到放满棋盘的64个格子。大臣们计算之后发现,要拿出这么多麦子,这个小小的王国无论如何是办不到的。264颗麦子够现在全世界的人吃几十年!
早期人工智能研究的一个中心课题是像下棋这样的游戏。这是因为在当时计算机的发明者著名数学家冯・诺伊曼(Von
Neumann)已经建立了关于游戏的理论基础“博弈论”而下棋又属于博弈论中最简单的一种情况“二人零和博弈"。二人是指只有两个人参加游戏,零和是说一方胜了则另一方为负,没有两人都胜的情况,一方的所得就是对方的所失,两人加起来得失之和为零。玩零和博弈的基本原则是“极大极小准则”,即要选择一种策略力求使自己的最小收益最大化。用一个简单的例子来说,假定我有A B两种策略,用A策略对方如果不注意会被我将死,但如果注意到会吃我一个车,而如果用B策略,则无论对方怎么下我都能吃他一个卒。按极大极小准则我应该选择B策略,而不应用A策略去下险棋,不能假定对方是个笨蛋。按照这个准则,再规定一组评价函数,例如吃一个车得10分,丢一个马得-6分等等,再把这些原则放到计算机里去,计算机就会对所有可能的走法算出分数,按极大极小原则选出最稳妥的一步棋。到此为止没什么大问题,问题出在后头。显然,只看一步棋是不行的,对手可以先给你点甜头
让你上当,然后把你杀个落花流水,为了取胜必须多看几步。假如对于每个棋局可走的方法有100种,对于每一种走法对方也有100种走法,看双方一步棋要算一万次,这对计算机来说不算多,可是要看双方两步就要算一亿次,用每秒一亿次的计算机要算一秒钟,如果看三步就得三个小时,看四步得三年,这棋就下不成了。
那么能不能用制造更快的计算机的办法来解决这个问题呢?回答是否定的。因为指数规律的增长实在太快了,而计算机受物理定律的制约,不可能作到无限大和无限快,速度受光速的限制,元件的缩小受测不准原理的限制,元件的个数受地球资源的限制。根据勃瑞姆曼极限(陈禹:《关于系统的对话》)的计算,一个由最小的元件构成的相当于地球质量的最快的计算机,从地球诞生时一直计算到现在,可以处理的信息量小于 1093位(bit,信息量的最小单位)。1093看起来相当大,但是指数增长却可以轻而易举地突破它。例如一个围棋盘有19×19=361个点,每个点可以有黑子、白子、没子的三个状态,那么所有可能的棋局就是3361>3194≈1093。看来与指数爆炸发生正面冲突就像鸡蛋碰石头。
那么能不能想出一个巧妙的算法来减少计算次数呢?这个问题涉及计算复杂性这一专门研究领域。一般认为,一类问题的计算复杂性是问题本身的性质,与算法无关。而且人的大脑也同样不能解决指数爆炸的问题。由此可以得到一个重要的结论:如果我们对大脑所作的模型遇到指数爆炸,必然说明这个模型与大脑中的实际过程相差甚远,需要重新考虑建立新的模型。换句话说,指数爆炸是提醒我们已经走错了方向的极好的警告灯。当然,指数爆炸的困难不是绝对的,如果问题的规模比较小,就能够在可以容忍的时间里得到解决。例如有一种圈叉游戏,只有3×3=9个格子,一方在格子里画圈,一方画叉,看谁先把自己的记号连成三个一排,这种游戏只有39=19683种棋局,用计算机下这种棋是很容易的。只是这种游戏没什么意思。
游戏的复杂程度差别很大,按照博弈论中二人零和博弈理论,任何这种游戏都有必胜或不败的方法。因为从一开局先走的人有有限种合乎规则的走法,而对应每一种走法对方也有有限种走法回应,如此反复直到分出胜负为止,就可以生成一棵“博弈树”,其中包含了所有可能的棋局。然后从树的末支(分出胜负的地方)向树根回溯,每次用“极大极小准则”算出上一级节点的胜负(或平局),回溯到树根时就算出了先走的人的胜负(或平局),由此可以推出后走者的胜负。对于比较简单的棋,例如奥赛罗,或是距离胜负步数较少的棋,例如五子棋,用这类方法可以编出很厉害的下棋程序。
象棋和跳棋比较复杂,由于指数爆炸的限制,除了“残局”之外,计算机不可能计算到最后胜负的地方。好在其中间结果(吃子、前跳)与最终胜负有关,吃掉对方的棋子,或避免自己的棋子被吃显然对取胜有利。但只凭“极大极小准则”编出的程序难以战胜高手,需要一些其他技术,例如关于棋局和定势的知识,或在对弈中自行改变战略的学习算法。
围棋是最复杂的。落子的近期效果容易评价,但远期效果的评价相当困难,或者说如何评价围棋的“势”是一个难题。所以下围棋的程序至今没有达到一段的水平。
早期的人工智能从玩游戏和证明定理出发,希望找出能解决所有问题的通用方法来,即开发“通用解题者”的程序。这一方面遇到了指数爆炸的困难,另一方面又让人感到不符合人思考的实际情况。人在下棋时显然不会考虑几亿个可能的棋局,只能借助知识在不太多的有希望的走法中选择。出于这样的认识,60年代后期人工智能开始转向对“知识”的研究,希望找到一种通用的在计算机中表现知识和利用知识去解决问题的方法。在这个时期出现了很多知识表现手法,例如声明型知识(什么是什么)、过程型知识(怎样做什么)、知识框架、剧本型知识等等,并制成了专家系统,把专家的知识放在计算机的知识库里,用这些知识解决一些专门领域的问题。这个研究方向也遇到一些共同的困难:第一是专家的丰富知识并不全是说得清楚的,有一些知识近乎直觉,说不清的知识不能形式化,也就无法放到计算机里去;与此有关的另一个困难是,这些知识表现方法都不是面向学习的,即机器不能自己学习新的知识,而真正要作出能应付实用的专家系统,需要的知识是非常大量的,这些知识由人一条条写好送到机器里去,其工作量有时会大得惊人,特别是考虑到人的日常生活中的知识(常识),其规模之大远远超乎一般人的想象。特别是除了严密的科学领域之外,一般的知识往往包含例外情况,而不考虑例外情况的专家系统一遇到例外就会出错。但考虑了例外则又会使知识极度膨胀,明斯基(M.Minsky)曾举了一个生动的例子来描述这种情况:“鸟能飞――如果不是企鹅或鸵鸟,如果还没死,如果翅膀没断,如果没有关在鸟笼里,如果脚没铸在水泥里,如果没有遇到过足以使其不能飞的心理上的恐惧经验。”[1]显然这些还远没包括所有的例外因素,何况例外之中还有例外,岔路上还有岔路。
上述的研究方向统称符号主义的方向。符号主义方向在学习方面存在着根本性的困难,这是因为人或机器能够直接从客观世界取得的信息都是模式信息,例如文字、图像、语音等等,而模式信息的处理又在符号主义的视野之外,要想直接从客观世界中获得知识,只处理符号是不够的。当符号主义方向的局限性日趋明显之后,和符号主义的历史一样久远而一度受到冷落的连接主义方向重新获得了重视。
20世纪40年代冯・诺依曼提出了计算机的基本结构之后不久,就研究过逐次处理的计算机与人脑的区别,提出了神经元网络型计算机的想法。50年代末罗森布拉特(F.Rosenblatt)试制了感知机(Perceptron)相当于双层的神经网,具备学习和处理模式的能力。60年代末,明斯基等人(Minsky,Papert)出版了一部名为感知机的专著,指出二层神经网只能解决线性可分离的问题,解决不了异或(XOR)问题,而多层神经网虽然能解决任意复杂的问题,却缺乏有效的学习算法。这个结论使得神经网的研究一度冷却下来。到80年代,出现了一些关于神经网的新算法,特别是Rumelhart和McClelland提出的误差反向传播算法(Back Propagation,简称B P算法),证明了多层网存在有效的学习算法,并实际解决了包括异或问题在内的一批问题,使得关于神经网的研究掀起了一个高潮。通过近年来的深入研究,神经网的局限性也越来越明朗化了,神经网的学习时间随问题的复杂程度呈指数增长。这里同样存在着指数爆炸。例如如果让神经网去通过示例学习区分质数与非质数的一般性方法是做不到的。值得注意的是,这种难度过高的问题人也解决不了,如果对一个会数数但还不懂乘除法的儿童提示大量的质数与非质数的实例,让儿童学到能判断一个未见过的数是不是质数,同样是做不到的。这使我们想起冯・诺伊曼在研究计算机与人脑的不同点时得到的重要结论:计算机可以处理逻辑深度很大的问题,而人则只能处理逻辑深度很小的问题。从这一角度上看,神经网的特性与人脑是相近的。但是如果把人脑看成是一个均匀的大神经网岁不仅不符合脑神经科学的现实,而且也会遇到数学上指数爆炸的障碍。大脑是由大量的小神经网模块整然有序组织起来的大系统。要想知道低能力的神经网怎样组成高能力的大脑,还必须知道更高层次的至且织原
则,这已经在神经网的研究领域之外了。
符号主义与连接主义扎根于不同的哲学土壤。从认识论角度来看,符号主义属于先验论的哲学体系,连接主义则属于经验论。现在看来两者各有其片面性,但是两者简单的合取或折衷未必能产生更好的认识论,这里需要新的哲学体系。
模式识别是人工智能的一个重要领域,其目标是把模式信息变换成便于计算机处理的符号信息。模式识别的处理对象范围很广,主要可以分为二维和一维模式两大类(三维以上的模式信息量太大,难以直接处理)。二维模式识别主要包括图像识别,文字识别,物体识别,纹理识别,景物识别,目标识别等等;一维则包括语音识别及各种波形识别。模式识别的过程大致可以分为两步:第一步是抽取特征,第二步是根据特征来判断模式应属于哪一类。第二步的判别在理论上比较成熟,而第一步的特征抽取则全靠系统设计者的技巧。特征抽取得不好,则整个系统识别的正确率大大下降。特征抽取的困难在于缺乏统一的方法,对于不同的目的,需要抽取的特征完全不同。例如在识别手写文字时,应尽量去掉由于不同的人写字的习惯不同而造成的变形,抽取区别不同文字的特征;而如果目的在于识别这字是谁写的,那么就要求抓住完全相反的特征。
模式识别的过程就是判别一个模式属于哪一类的过程,识别的前提是分类。在识别之前人或机器内部必然已经存在一个类别系统,否则不可能判断模式属于哪一类。如果我们能够知道人脑中的类别系统是怎样生成的,或者说知道类别系统本身是按什么特征组织起来的,那么按照相同的特征去进行识别,应该是万无一失的。如果我们再进一步能知道人脑按什么原则去选择特征来建立类别系统,那么我们就能找到自动决定如何抽取特征的方法,不必再依靠就事论事的技巧来设计模式识别系统。这里得到的启发是:识别(Recognition)就是再认知(Re-Cognition),要想弄清楚识别就必须先弄清认知的过程,其中包括人是怎样在大脑中建立类别系统的。这种看法好像是把一个简单问题变成了一个更困难的问题,但是如果非此不能解决“简单”问题的话,那么这条“弯路”还是非走不可,就像三等分角和五次方程求根这种貌似简单的问题却需要高深的数学工具才能解决一样。
20世纪60年代,美籍日本学者渡边慧证明了一条著名的定理――丑小鸭定理。这条定理的主要内容是,世界上所有事物之间的相似程度都是一样的,丑小鸭与天鹅之间的差别与两只天鹅之间的差别一样大。从这条定理可以得到的一个推论是,不存在“纯客观”的分类准则,人进行分类所依据的一切准则都是主观的,而选择什么准则进行分类则纯属主观评价问题,是一个涉及到价值观的问题。为了解释这个看起来违反常识的定理,渡边慧举了一个例子:按生物学的分类准则,鲸是哺乳类与牛属于一类,而与鱼不同类;按产业界的分类,捕鲸业属于水产业而不属于畜牧业,鲸与鱼在一类而与牛不同类。这种分类准则的不同源于分类的目的不同。因而选择特征时所持的价值观也不同,这些都是主观因素而非客观因素。
科学是要求客观性的。从中学作理化实验开始,教师就教我们读表针和看量筒如何避免主观误差。价值观因人而异,在作科学论证时,“我就喜欢这样”是不能作为论据的。因而考虑主观因素的议论,似乎已经超出了科学研究的范围,这就是研究认知所遇到的一个重大的困难。要克服这个困难,须要重新讨论一些问题,例如客观性意味着什么?评价有没有客观标准?等等。这些问题都涉及哲学,解决这些问题需要哲学层次的分析和研究。
实现机器翻译,是早期人工智能研究的一个中心课题,为此很多国家设立了庞大的研究计划,投入大量资金研究开发机器翻译系统。20世纪60年代后期,美国的一个研究机关提出了一份报告书,认为近期内开发机器翻译系统是不现实的,机器翻译一度冷却。80年代又有一部分人认为当时机器翻译的困难是由于硬件能力不足,现在有了能力很强的计算机,已有条件研究机器翻译,又形成一个机器翻译热,但时至今日,也还没有一个令人满意的机器翻译系统问世。
几十年的努力决非徒劳无功,除了可以开发出提高人的翻译效率的辅助系统之外,至少我们对于机器翻译所遇到的困难比较清楚了。机器翻译的困难包括表层的困难和深层的困难。表层困难之一是语法的例外,人所实际使用的语言(自然语言)与计算机语言不同,语法现象经常出现例外,这使得计算机中需要存储的语法庞大得难以实现,有时甚至关于一个词也要有很多条语法。另一个表层困难是词的多义性,只要查一下词典就可以发现,自然语言中的一个词可以有多种含义,而一种意思也可以用很多词表达。在众多的语义和表达之中选择最佳者对于计算机来说相当困难。然而,人在用自己掌握的自然语言进行会话时对于这些困难甚至感觉不到。这是由于人可以理解语言的语义,而机器则很难做到这一点,这是一个深层的困难。实际上,由人来作翻译时对于不理解的东西也是无能为力的,这也就是为什么专业著作的翻译必须由懂得该专业的人来完成,而一般非专业性的翻译也要求对于两种语言各自的文化背景有足够的了解。
虽然人们很早就知道翻译只靠语法和单词对应表是不够的,必须依靠语义信息,但是关于语义的研究所获不丰。这里的困难在于,理解总是需要一定的背景知识,而如前文所述,建立一个相当于一般人所拥有的常识的知识库是非常困难的。如果一个机器系统能像人一样,从少数的知识出发,通过对语言的理解,逐步增加其知识,就有希望通过学习得到一个知识丰富的系统。为了达到这个目的,我们需要对理解的过程有更深的理解。理解作为动词使用时,指从不理解的状态进入理解状态的过程。这个过程我们称之为“解释学的循环"。即通过理解或解释,我们可以把少数的知识扩展出一点,而扩展后的知识又使我们能理解的范围扩大,使原来不能理解的东西有一部分变为可理解的,只要实现了这个循环,就可以像数学归纳法一样无限地扩展知识。怎样在机器上实现解释学循环是一个很重要的问题,也是个困难的问题。
通常的计算机系统不具备学习能力,我们称之为L0型系统,在L0型系统中追加一个学习程序,使得L0型系统能在学习程序的控制之下改变其参数或结构,这个系统就获得了学习能力成为L1型系统。.现在常见的学习系统几乎都属于Ll型系统。如果希望学习系统能在学习过程中提高学习能力,应使L1型系统中的学习程序本身也可以改变,这就需要追加一个控制一阶学习程序进行学习的二阶学习程序,构成L2型系统。按这条路走下去,为了得到高度的学习能力,需要建立一个L∞型系统。这就会引起无限退行的困难,一个有限的物理系统装不下无穷多个学习程序。为了克服这个困难,要在有限的系统中实现无穷的学习能力,需要一个环状的结构,即可以改变自身的学习程序,或者说知道自己在干什么的系统。从这里我们可以得到一个启发,一个具有高度学习能力的系统,必须是一个有意识的系统。人脑的高度的学习能力与其意识是分不开的。而怎样建立起具有意识的系统也是一个困难的问题。
人脑与计算机的一个重要的区别在于,人脑具有创造性而计算机只能按程序行事,不敢越雷池一步。创造意味着作出不可预知的好结果。“不可预知"与“好”是两个缺一不可的因素。对于可以预见的结果,我们通常不认为是个创造,同样,对于机器的偶发故障或是掷骰子得到的数字集,虽然不可预知,但由于不满足“好”的标准,通常也不算创造。
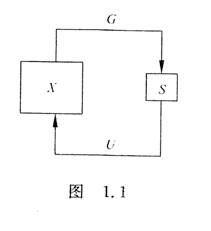
按照这两条标准,阿希贝(W.R.Ashby)提出的“超稳定系统”可以算是有创造性的机器的最简单的模型(图1.1)。这个模型由X和S两部分组成,当X的状态使得输出G不满足条件n时,S不断发出随机信号通过u使x不断变化,直到x的状态使G满足条件n,则s进入静止状态,不再发出随机信号,机器进入稳定状态。在这个系统中,随机信号是不可预见的,条件n则是“好”的标准。
我们用一个具体的例子来探讨一下实现这种系统的困难在何处。假如要用这个原理来设计一台自动作诗机(作诗当然是一种创造活动),诗中所用的汉字限于第1级和2级的6千多个字,只限于作五言绝句,每首诗20个字。作诗机中相当于S的部分每次发出1~6000的20个随机数,X按这些随机数依次选出20个汉字排成一首“诗”,X还包括一个判断是否是好诗的功能,如果不是好诗,则由G送出一个信号,让S再发下一组随机数,如果是好诗则让S暂停,把诗打印出来。
实现“作诗机”有两个显而易见的困难:第一个困难是指数爆炸,6000 20是个相当大的数,如果要作七言律诗,则已超过了勃瑞姆曼极限;第二个困难是如何让机器具有判断好诗坏诗的能力,即如何让机器富有诗意。要克服第一个困难需要一种回避指数爆炸的方法,要克服第二个困难则要有一种机器能够接受的美学理论或评价理论。在“发现有价值的新定理”这一任务中,也遇到与此相似的困难,计算机虽然可以推导出新的定理,但是,一者“岔路前头还有岔路",二者缺乏适当的准则去自动评价一个定理是否“有价值”,是否符合作为一个定理的“美学”要求。
图灵(A.Turing)大概可以说是最早深入地思考“机器能否思维”这一问题的人。他不仅对这一问题作出了肯定的回答,而且提出了检验机器是否能思维的具体方法――“图灵试验(Turing test)”。图灵试验的基本想法是:两个人在相互看不见的地方通过电传打字机进行对话,如果一方的人无法区别与之对话的是人还是计算机,计算机就通过了图灵试验,可以说计算机能够思维了。图灵试验既是一种测试方法,又可以说是思维的一种定义,一种“行为主义”的或是“操作主义”的定义。关于思维的这种定义基本上是令人感到可以接受的,因为我们可以同意“思维”与外形、说话的语调无关,当一个人的外貌严重受损,发声器官破坏时思维可以不受影响,按照一般的生活经验,我们可以通过对话对别人的思维能力作出正确的判断,而且图灵试验对于谈话的内容不作任何限制。图灵试验是相当严格的,以至于至今还没有人编出能通过图灵试验的程序。
图灵试验虽然有其令人可以接受的一面,但其行为主义基础却有很明显的缺陷。行为主义是心理学界流行过一个时期又被否定了的研究方针,其基本主张是进行心理学研究时反对一切内省和推测,只从可观测的行为出发,以保证心理学遵循科学所必须重视的客观性准则,排斥诸如意识、感情、知觉、目的、意向之类的依赖主观观察的用语。对于简单的系统,行为主义方法可能奏效,但对于复杂系统,特别是像人脑这样的复杂巨系统,行为主义显然无能为力,相同的行为背后显然可以有不同的内部状态与之对应,单靠行为来推断人脑的内部状态和过程是不现实的。举个简单的例子来说:在地上固定一根铁管子,管壁上遍布压力传感器,管子里有一个全电子化的录音设备,事先录好惨叫、喊疼、谩骂、呻吟等各种声音,只要电源一开,机器可根据所受撞击的大小、频度,次数等选择不同的声音播放出来,当我们用棒子打这个铁管时,其行为可以与感觉到疼的人惟妙惟肖。现在的问题是“这个机器能真的感
觉到疼吗?”从行为主义的立场看,应该回答“疼”,而我们如果知道这台机器的内部构造,肯定回答“它不疼”。这里涉及一个古老的哲学问题:“子非鱼,安知鱼之乐!”如今是20世纪了,两千多年以前的问题也该有个了结。对于机器疼不疼的问题,如果不能靠行为主义下结论,就得解决一个问题:一台机器具有什么结构或功能就可以认为它感觉到疼了呢?这个看起来极难的问题可以用进化论的方法论找到一个线索。进化论的方法论允许我们对于生物的性状提出这样的问题:这种性状为什么在生物的进化过程中不被淘汰?或者用其简化形式:这种性状对生物有什么好处?如果知道“疼”和“乐”有什么用处,就有可能推测出“疼”和“乐”要求哪些功能,需要用什么样的结构来实现这些功能。有了这些知识,不仅可以从机器的结构上分析机器是否真的感觉到疼,而且有助于我们设计一台能觉得疼或乐的机器。这也是本书为什么把进化论作为核心理论的原因之一。
图灵曾经深入地考虑过很多关于机器思维的问题:能不能在有机的、电子的或是其他的物质基础上实现真正的智能?心灵是否不仅仅是模式?我们怎样才能区别真正的心灵和仅仅看起来像心灵的巧妙制品?自由意志是不是与唯物论者的机械论生命观不能相容?由某种规则规定的创造性的想法是否含有某种矛盾?我们的感情与知性是否属于我们自身的不同部分?机器会不会迷恋上某种新奇想法、某个人或另一台机器?机器会不会相互之间感到魅力而堕入情网?堕入情网的机器之间存在什么样的社会通用准则?机器的恋爱有无正当与不正当之分……
霍夫施塔特(Douglas R.Hofstadter)在罗列这些问题时[2]不乏幽默感,但是这些问题无疑是非常重要的,包括图灵在内的每一个思考机器能否思维的人都无法回避这些问题。如果在1 9 5 4年,年仅4 2岁的图灵没有由于英国的陈腐道德观念和野蛮的医学理论而身心受到极度摧残被迫害致死,而是逃到自古以来对同性恋持宽容态度的中国,这位刚过80大寿的老学者大概可以为我们作出这些问题的解答。但是图灵试验的行为主义立场对这些问题却是采取回避而不是正面解决的态度。大概经过深思熟虑之后,图灵也认为回答这些问题极为困难,因而行为主义的立场更为安全可靠。行为主义的合理性在于,我们每个人都不能进入他人的内心世界,直接观察他人是否和自己一样有意识、有感情、有知觉,只能通过他人的行为间接地判断。如果不承认这种间接判断,其结果必然导致唯我论,认为世界上只有我一个人存在,这显然是非科学的态度,因为任何科学的活动,例如发表论文,都只有在假定他人存在时才有意义,否则写书写论文给谁看呢?
但是行为主义也有不尽合理之处。如果我偶然踩了猫的脚,听到一声尖叫,我对于猫会感觉到疼这一点毫不怀疑,但是如果这是一只制作精巧的玩具猫,我会有完全相反的结论。把对待他人的态度直接推广到机器身上有其不自然的一面。在人工智能学界不乏这样的例子,某个人工智能程序在进行演示时表现非常出色,但是一旦人们了解其内部工作原理,总是异口同声地说:“这不算智能”,弄得一些人工智能专家也抱怨说:“不知道的都是智能,一旦会作了就都不是智能了。”这里有个奇妙的现象,谁也不知道真正的智能程序是个什么样子,但是谁都能判断某个程序不是真正的智能。这种神秘的直觉从何而来呢?这个貌似困难的问题其实非常简单,虽然谁也不知道真正的智能程序是个什么样子(因为世界上还没有这样的程序),但是每个人都拥有这样一个程序(自己的大脑),谁也不知道自己的大脑是怎样运转的,但是每个人都能观察自己大脑的某些运行结果。我们只要核对智能程序的中间过程与自己大脑运行的可观察到的部分是否一致,就可以判断某个程序是否真的有智能。要知道烤鸭的滋味只要吃过就行,要判断吃的是不是正宗并不需要知道烤鸭的全部工艺过程。
行为主义巧妙地回避了意识和感情这样的困难问题,但是也因此就拒绝了研究意识和感情对于研究智能的帮助。这样做得不偿失,因为机器的好处恰恰在于我们容易观察其内部,而机器又缺乏像猫一样和人类在进化上的同宗作为对类似行为作类似解释的理由。每个人都知道自己有意识、有感情、有知觉、有目的,一个自称智能的程序或是关于智能的理论不对这些现象作出说明是不能令人信服的。哪怕你说这些都是误解或幻觉,也得说明产生这些幻觉的理由和机制。意识、感情、知觉、目的等等的困难问题,如同疼不疼的问题一样,也可以依靠进化论的方法论,通过研究这些现象在智能活动中的作用来给以解决,同时也就解决了智能的问题。
听说美国有一股势力主张在学校讲授进化论的同时也应该讲授神创论,有一定文化水平的中国人对此大概都会感到惊奇。但是我却有幸从企图向我传教的人那里借到一本反对进化论的书,其中反对进化论的理由竟然是我们为之烦恼已久的指数爆炸,着实令人茅塞顿开。反进化论的理由是这样的,生物的基因中包含着极大的信息量,例如人类基因信息量可以抵上一座大规模的图书馆,靠随机的方法去生成如此之大的有序信息所需要的时间显然远远超过宇宙的寿命。这个计算是不错的,一首七言律诗就够吓人的了,何况一个图书馆。但是人毕竟出现了,这说明进化的机制中包含着回避指数爆炸的算法。进化是自然界中自发实现的最富成果的创造活动,对于创造的两大问题指数爆炸和评价,都提供了解决的指南,没有人参与的进化,其评价不可能是主观的,只能是客观的。这是本书把进化论作为核心理论的主要原因。
进化用以回避指数爆炸的原理我们称之为“麻将原理”。如果我们的麻将规则要求只发牌不打牌,发好牌后如果没“和”就又洗牌重发,那么我们可能打一辈子麻将也没“和”过一次,问一问常打麻将的人就可以知道,刚发到手的牌就是“和”的概率是非常小的,其原因就是指数爆炸,但是只要打牌,不管开始手中的牌有多坏,总能在可以容忍的时间内让牌“和”了,虽然我们摸牌时仍是随机的,但通过逐步的选择,淘汰不要的牌,可以逐步逼近“和”的状态。这相当于进化中的变异与选择原理。
按照进化论的麻将原理,我们可以设计第二个版本的作诗机。这种作诗机不是一次发生20个字,而是每次随机发生一个字,经过选择认为这个字作为诗的第一个字很好就固定下来,不好就弃之重选,第一个字固定后按同样方法选第二个字,直到20个字完成,每个字选择时都要顾及已固定的字的影响。第二版作诗机仍存在评价与选择的困难,但指数爆炸已经不存在了,选择的次数充其量不过6000×20=120000,这是可以容忍的。字集的总字数为M,诗的长度为N时,第一版作诗机的计算时间为MN,第二版为MN,与长度成线性关系。
当然,指数爆炸的问题并不都是可以用这种方法对付的,进化所包含的原理也并不仅仅限于一个麻将原理,否则这本书也就没有必要再写下去了。现有的所谓“遗传算法"是应用麻将原理的一个实例,但是这个算法并没有显示出明显的优越性。为了弄清进化回避指数爆炸的更丰富的内容,我们需要对进化的过程进行更深入的研究。