§
12.7 斩乱麻问题 “斩乱麻问题”是体现最复杂原理的简单又概念清楚的例子(参考1997年12月《数理统计与应用概率》杂志上我与马力写的同名文章)。它是说有一条充分长的绳子用刀随机切割成很多小段。问不同长度的线段各有多少。从表面上看这个问题几乎没有给任何已知数,反而要求你给出一个函数作为答案。做惯了一般数学题的人可能感到无从下手。但是,当你掌握了广义集合和分布函数概念以后,就会看到本问题的答案符合“不同的某某某各有多少”的问题模型。所以本问题就是把一堆乱麻看成一个广义集合而寻找它的分布函数。于是前面的知识都可以拿来应用。
由于切割是随机的,所以不可能要求切割的每个线段都有相同的长度(这种情况出现的概率最小)。线段有长有短就构成了它的复杂性。如何定量表示其复杂性?用我们定义的复杂程度。如何估计这个复杂性的大小?显然应当在条件允许的情况下对其复杂程度做最充分的估计。变成定量语言,就是不同长短的线段所对应的复杂程度应当充分大。说得再专业些就是该复杂程度应当最(极)大。
认识到复杂程度应当最大,就可以以此为判据反求分布函数了。求分布函数时利用了这个判据就是利用了最复杂原理或者最大熵原理。
在线段长度x为连续变量的情况下,它的分布函数为f(x)的含义是长度在x到x+Δx范围的线段占的百分比为f(x)Δx 。而它的复杂程度C应当是(设N是线头的总数) C=-∫Nf(x)lnf(x)dx利用拉格朗日方法解这个未知函数还要利用约束条件。本问题中有什么约束条件呢?
所谓切割这根长线仅是把它变成很多短线,而不是把线烧掉。所以很多短线头的长度的合计值显然应当等于原来的长线的长度L,根据分布函数的含义,显然有 L=∫Nxf(x)dx (12.8) 即线头总长度是各个线头的长度与其占的百分比的乘积再乘以线头总数N 的积分。而各个线段的百分比[f(x)Δx] 的积分(合计值)显然应当等于100%,即 1=∫f(x)dx (12.9)(
12.8)和(12.9) 分别表示两个约束条件,其含义是各个线段的合计值与原线长度相等、各个线段的数量的合计值与总的线段数量相等。L,N 就是两个常数。它对应于上一讲中的k1,k2(仅有两个约束,所以m=2),根据上讲,新构造的函数应当是 F=-∫f(x)lnf(x)dx +C1[∫xf(x)dx- L/N] +C2[∫f(x)dx- 1] (12.10) 这里的C2,C2是与L,N有关的待定常数。根据上节得到的解,使复杂程度极大对应的分布函数应当是 f(x)=exp(-1+C1x+ C2)利用
(12.8)和(12.9)与本式联立可以消去未知数C2,C2引入已知数L(线长),N(线头总数)解得 f(x)=(N/L)exp(-Nx/L) 注意到L/N 的含义是线头的平均长度,以a 表示它(也是常数),我们得到 f(x)=(1/a)exp[-(x/a)] (12.11) 它是一个负指数分布函数。即斩乱麻问题的答案为负指数函数(相对密度分布函数)。它显示长度x短的线头多而长线头依负指数公式就很少。 根据相对密度分布函数的定义,线头长度出现于x→x+Δx 范围情况有Nf(x)Δx 个。例如L=200米,切成N=20000段(平均值a=1cm),可以计算出长度在3→4 cm范围的线头有(计算中用的3.5cm,它是3-4的平均值) 20000f(3.5)Δx =20000f(3.5)(4-3)=20000(1/1)[exp(-3.5/1)](1)=604
即长度在3→4 cm的线头有604段。它占了总量的3% 。 公式(12.11)就是以相对密度分布函数形式表示的斩乱麻问题的结果,它是一个函数,而且是负指数形式的函数。显然有了这个函数,我们可以方便地计算在各个范围的线头的数量和百分比或者线头长于(短于)某个值的共有多少。这些具体计算利用一般积分知识都不难做。这里就不细说了。§
12.8 斩乱麻数值实验(计算由美国田纳西大学研究生崔旭完成) 前面得到的是斩乱麻问题的一种理论结果,它符合实际吗?最好是用实际实验检验它。但是即便碎线头有1000段,做这个实验也很费力。有没有其他的检验方法?电子计算机的普及把所谓计算机上的数值实验提到了“科学实验”的舞台上。这里介绍如何组织一个数值实验而得到一批数据。让它既符合原问题的要求,又没有利用最复杂原理。如果这些数据与最复杂原理推得的负指数分布没有明显差别,我们也就从统计学角度证明了用最复杂原理解决斩乱麻问题的思路是正确的。
下边利用计算机来模拟斩乱麻试验。这里核心问题是用计算机产生一批数据,它们恰好具有斩乱麻问题中的各个线段长短不齐的特点。这类数据在计算机和数学中这称为随机数。最基本的随机数就是均匀分布在一定范围中的随机数。数值试验可以利用目前广为应用的微软公司的Office 软件中的Excel 软件完成。大家知道这个软件是一个进行表处理的软件,它还具有良好的计算与统计功能。所以计算可以不编程序,让它生产一批随机数做下面的处理就得到了代表不同长度的线头了。 假设有一根长为10,000m的绳子被随机地切了999刀,我们可以按照下面的步骤模拟:| 在0-10000范围内产生999个随机数。 |
在Excel 软件中,只要打开一个空白的表,利用RAND 函数功能就可以在第一列的最上端产生一个随机数。把鼠标选在那里按住鼠标向下拉,立刻得到999个随机数(在第一列)。
这样得到的随机数是界于0到1之间的。把它们都乘以10000,就得到了999个界于0到10000之间的随机数。这些随机数服从0-10000的均匀分布,它们就是乱麻被斩后的断点。
将这些随机数从小到大排列,并将0和10000分别加入首和尾,这样就得到一个新的序列A。它代表了999刀在10000 m长的线上的排列位置。 | |
计算序列A的相邻数值的差。这些差值就应当是“被切后的1000根绳的长度”。 | |
统计这些线段的长度的分布。即在0-5 m,5-10 m等区间的线段的个数占总个数(1000)的百分比。统计不同长度的线段各有多少(%),就得到了斩乱麻的具体的线段长度的分布函数。 |
| 把上面得到的线段长度的分布与理论预测比较。根据理论预测,这些绳段长的分布应服从:f(x)=0.1exp(-0.1x). 因此长度在a 到b 范围的绳子占的个数的百分比F 应为这个函数在(b-a)区间的积分。 |
(这里用F 表示f 的积分,它与介绍拉格朗日方法中的F 含义不同),下边是模拟试验的数据:
A rope, which is 10,000 meter long, is cut for 999 times. The cutting point is uniformly distributed along the rope. Thus we get 1,000 small ropes. The distribution of the length of the ropes is listed below. |
rope
length /meter |
simulation
% |
theoretical
% |
0-5 |
39.70 |
39.35 |
5-10 |
25.10 |
23.87 |
10-15 |
13.90 |
14.47 |
15-20 |
7.40 |
8.78 |
20-25 |
4.80 |
5.33 |
25-30 |
4.30 |
3.23 |
30-35 |
1.70 |
1.96 |
35-40 |
1.00 |
1.19 |
40-45 |
0.90 |
0.72 |
45-50 |
0.30 |
0.44 |
50-55 |
0.10 |
0.27 |
55-60 |
0.30 |
0.16 |
60-65 |
0.20 |
0.10 |
65-70 |
0.00 |
0.06 |
70-75 |
0.30 |
0.04 |
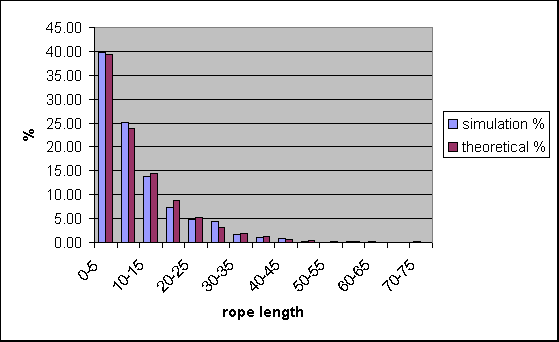
比较模拟试验的数据和理论值,发现模拟数据吻合预测值。这样我们就证明了用最复杂原理解决斩乱麻问题的思路是正确的。下面是对应的图。
图12.2斩乱麻的数值试验数据(兰色)与理论数据(深红)的对比
图的横坐标是绳的长度(米,m),纵坐标的该长度的绳子的数量占的百分比
----§12. 9 再谈最复杂原理----