A New Iteration Algorithm for
Maximum Mutual Information
Classifgications of Factor Spaces
――Based on the Semantic
Information Method
CHENGUANG LU
Professor (retired, Living In Canada)
Liaoning Engineering And Technology University
Abstract:
The factor
space is also the feature space of instances or true classes. We use “factor” because observed factors
instead of any property are used as
features. In detections, estimations, and classifications, signal X is mixed
with noise to become Z, or the factor Z of class X is observed. We need
classifier Y=f(Z) to predict X by Y. Shannon and others use minimum average
distortion instead of Maximum Mutual Information (MMI) as the optimization
criterion because it is very hard to solve the MMI. Without f(Z), we cannot
express mutual information I(X; Y). Without the expression, we cannot optimize f(Z). An expedient method is
first to construct likelihood functions or Shannon's channels with parameters,
and then to search the parameter space by the gradient descent or the Newton
Method. According to the semantic information G theory, we can use a simple iteration algorithm to resolve this problem.
The semantic information measure is Iij=log[T(θj|xi)/T(θj)], where T(θj|xi) is
a truth function, and T(θj) is its average. The average G of Iij is the
Semantic Mutual Information (SMI). For given f(Z), there is information
Iij*=log[P(yj|xi)/P(yj)]. In this algorithm, Step I is to let Iij= Iij*, and
Step II is to optimize f(Z) to maximize G by the KL formula. Our experiments show that 2-3 iterations can
make I(X;Y)
reach 99% of the MMI in most cases. The convergence can be proved with the R(G) function, which is an improved R(D)
function. The R(G) function is a bowl-like curve with a matching point G=R, which
means R≥G always. The Step I makes G=R and produces a new R(G) with a higher
matching point. The Step II makes G climb to the upper right corner of the new
R(G) function. Repeating the two steps can achieve the MMI. Reference:
https://arxiv.org/a/lu_c_3.html
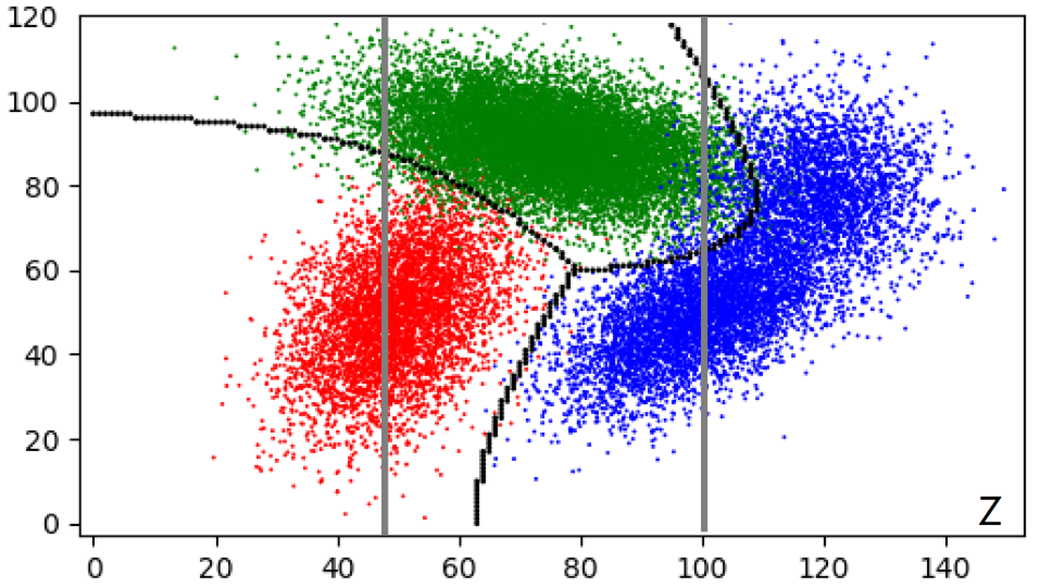
Fig. 1 The Maximum Mutual Information (MMI) Classifications of a Factor
Space. The initial partition of Z-space is made
by two vertical lines. After two iterations, the partition is made by
three curves so that the mutual information reaches 99.99 of the MMI.